第17期--重庆南滨路夜市
一、刊首图

热闹的重庆南滨路夜市,就在长江边上,江对面就是渝中半岛的高楼。
二、时事新闻
1、环保奥运会
巴黎奥运会将于7月26日开幕。组委会宣布,这是一届环保的奥运会。但是,它的环保措施让人有一种简陋的感觉,似乎更大的目的是为了省钱,毕竟巴黎市的财政并不宽裕。这次的奥运村不是专门新建的,而是现有楼房改建的,阳台也是改建过程中添加的简易阳台。室内就更简单了,床是纸板床,甚至椅子也是纸板做的,所有房间都没有装空调。
萝卜快跑无人驾驶出租车,正在街头接送乘客,不过目前还不是彻底的无人驾驶,每辆车都有人在云端监控,紧急情况下会远程接管。萝卜快跑现在12个城市运营,其中4个城市是车内无人,其余都是车内有安全员。武汉是唯一可以全市范围内 7X24 小时运营的城市,其余均只能在指定区域的部分时段内运营。武汉的政策最宽松,2022年就发布了“三个允许”:允许车内无安全员、允许开上社会道路、允许商业化服务。

萝卜快跑火了以后,其他城市快速跟进。7月8日,上海宣布,允许车内无安全员,最快一周内面向公众测试无人驾驶出租车。中央政府也明确支持,并且推动“车路云一体化”,作为国家的发展方向。北京市更是明文规定,今后新建、改建、扩建道路,都要在道路两侧为智能化基础设施预留空间。总之,无人驾驶已经不是实验室技术了,全国铺开测试、大规模应用,即将到来。
3、微软蓝屏事件
北京时间7月19日,美国网络安全公司CrowdStrike软件bug带崩了全球范围内的微软Windows系统,外媒将此称为“史上最大规模IT故障”。全球范围内,包括航空公司、医院、铁路网络和电视台在内的关键企业和服务都因微软系统中断而瘫痪,就连美国911电话的接线员都无法对紧急情况作出回应。此外,全球供应链也受打击,其中,高度复杂的航空系统受创最为严重,航空运输可能需要几周时间才能恢复正常。
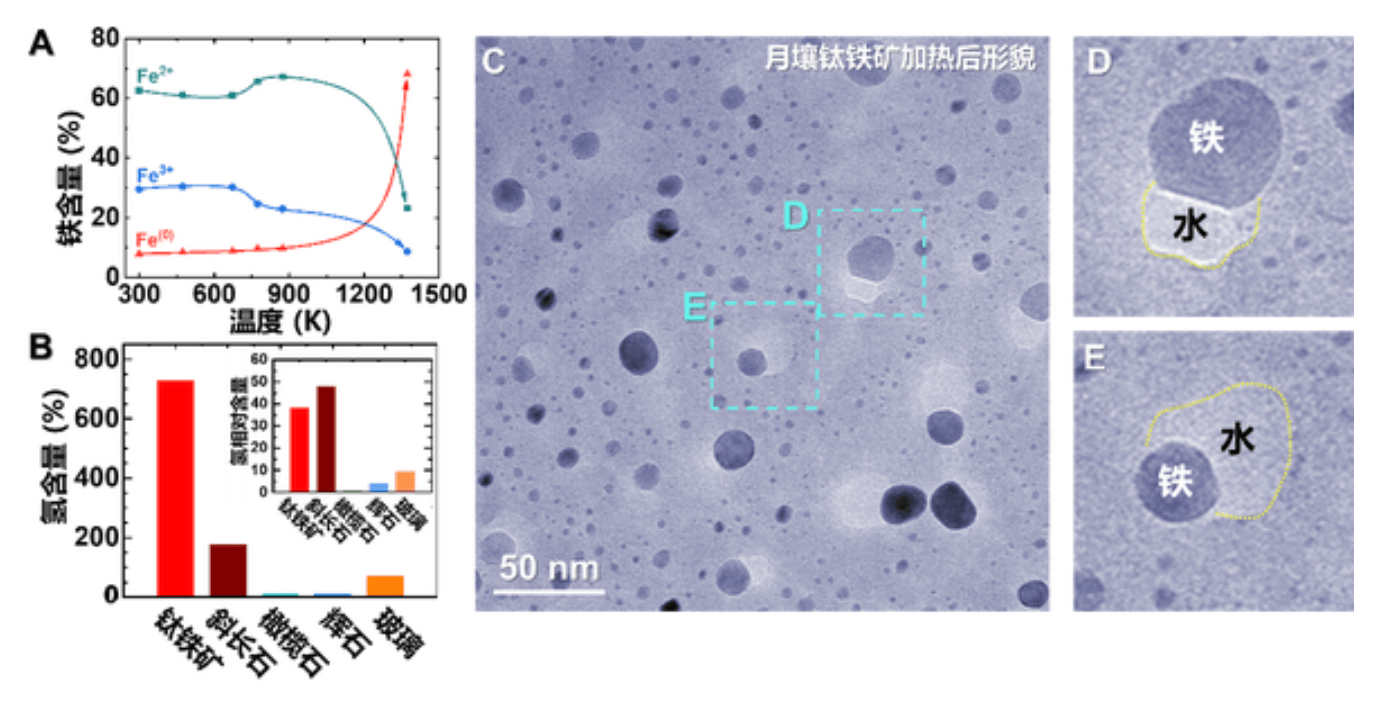
4、月壤造水新方法
我国嫦娥五号月壤研究发现了一种通过加热月壤生产水的新方法,为月球科研站和空间站的建设提供了新思路。研究表明,月壤中由于太阳风辐照积累了大量氢气,通过高温加热可以与矿物中的铁氧化物发生反应,生成单质铁和水蒸气。实验发现,每克月壤可以产生51-76毫克水,1吨月壤可产51-76千克水。此外,研究还发现月壤中的钛铁矿是月球“蓄水池”,在加热后能生成大量水和单质铁。这一发现为未来月球探测和开发提供了重要参考。
9月12日,OpenAI发布新模型o1系列,可以实现复杂推理,旨在花更多时间思考,然后再做出响应。这些模型可以推理复杂的任务并解决比以前的科学、编码和数学模型更难的问题。具体来说,o1系列是OpenAI首个经过强化学习训练的模型,在输出回答之前,会在产生一个很长的思维链,以此增强模型的能力。内部思维链越长,o1思考得越久,模型在推理任务上的表现就越好。
在刚刚结束的2024 IOI信息学奥赛题目中,o1的微调版本在每题尝试50次条件下取得了213分,属于人类选手中前49%的成绩。如果允许它每道题尝试10000次,就能获得362.14分,高于金牌选手门槛,可获得金牌。另外它还在竞争性编程问题 (Codeforces) 中排名前89%,在美国数学奥林匹克 (AIME) 预选赛题目中跻身美国前500名学生之列。
详见官方介绍文档:https://openai.com/index/learning-to-reason-with-llms
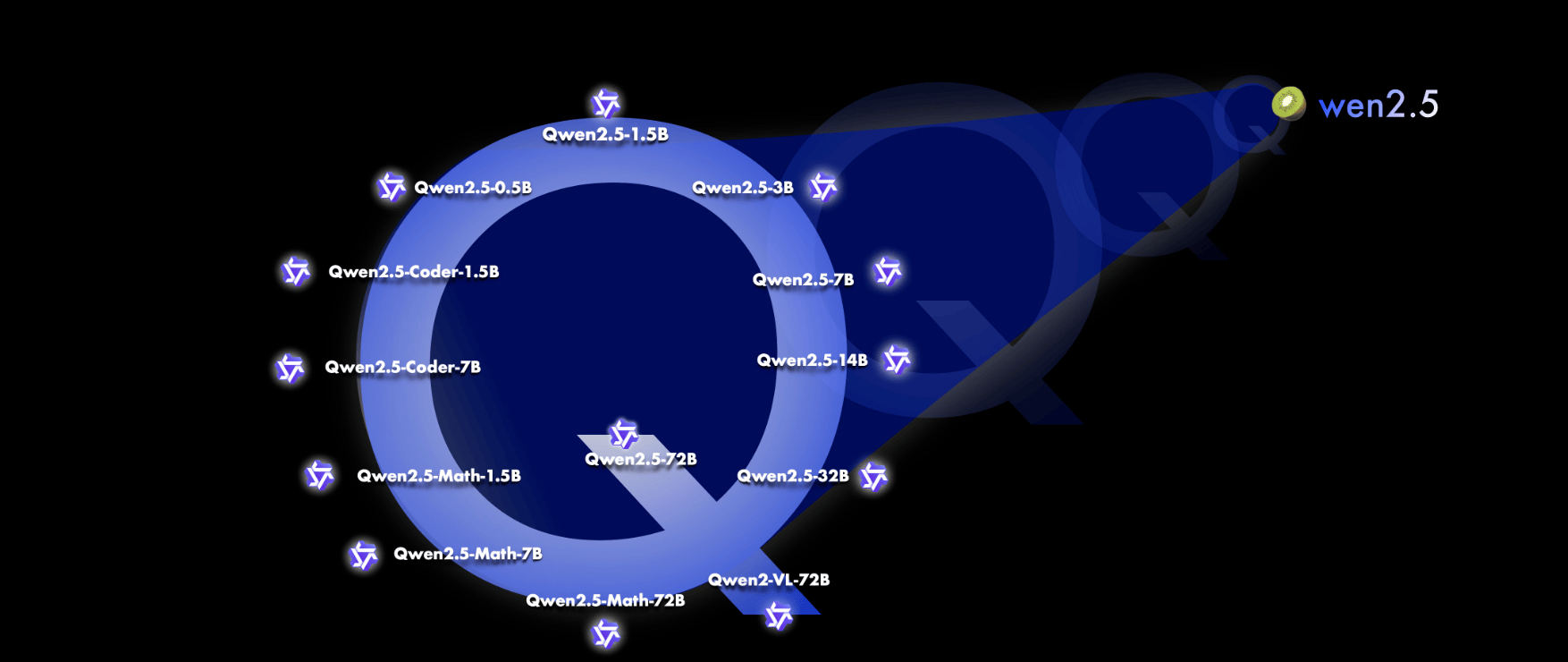
9月19日,阿里发布了Qwen2.5系列模型,包括语言模型 Qwen2.5,以及专门针对编程的 Qwen2.5-Coder 和数学的 Qwen2.5-Math 模型。所有开放权重的模型都是稠密的、decoder-only 的语言模型,提供多种不同规模的版本,包括:
- Qwen2.5: 0.5B, 1.5B, 3B, 7B, 14B, 32B, 以及 72B;
- Qwen2.5-Coder: 1.5B, 7B, 以及即将推出的 32B;
- Qwen2.5-Math: 1.5B, 7B, 以及 72B。
9月14日,阿里云盘被曝出存在一个“灾难级的严重bug”。有用户偶然发现,在阿里云盘的相册功能中,只要创建一个文件夹并在分类中选择图片,竟然可以看到其他用户云盘里的图片。虽然此次bug的影响范围尚难以准确评估,但众多用户的反馈表明,此事件已引起广泛而高度的关注,不少用户对此可能造成的隐私泄露深表震惊和担忧。
三、技术文章
1、LLaMA 3.1结构及影响解析(中文)
LLama 3 405B模型效果已经接近目前最好的闭源模型比如GPT 4o和Claude 3.5,官方的技术报告接近100页,信息很丰富。本文作者就LLaMA 3的模型结构、训练过程做些解读,并对其影响、小模型如何做、合成数据等方面谈点看法。
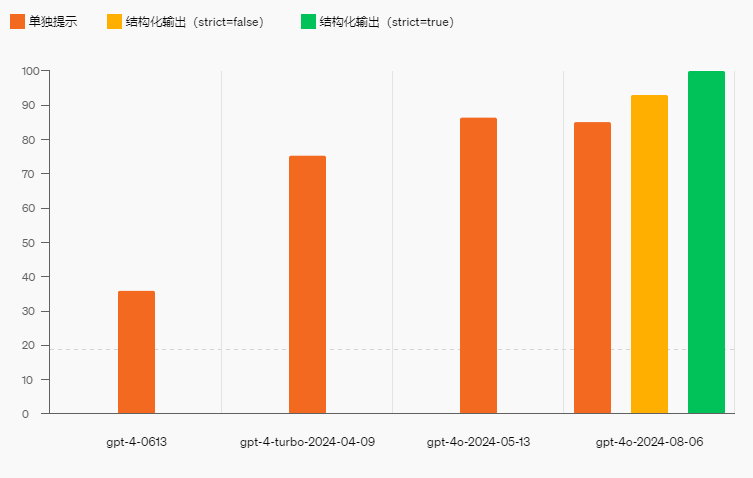
2、OpenAI支持100%结构化输出(中文)
通过设置 "strict": true 参数,可以实现结构化输出,模型输出将与提供的格式定义相匹配,此功能适用于OpenAI的所有模型。其中,OpenAI刚发布的gpt-4o-2024-08-06模型,可以实现输出JSON的100%准确率。
四、开源组件
Omniparse 是一个开源文件解析平台,可以将任何非结构化数据(文档、表格、图像、视频、音频文件或网页)解析成结构化、可操作的数据,并针对 LLM 应用程序进行优化。它支持多种文件类型,可以提取表格、图像、音频/视频转录、网页爬取等功能,并可以使用 Docker 轻松部署。

2、GraphRAG
微软开源的 GraphRAG 是一种基于图的检索增强生成方法。通过 LLM 构建知识图谱结合图机器学习,GraphRAG 极大增强 LLM 在处理私有数据时的性能,同时具备连点成线的跨大型数据集的复杂语义问题推理能力。普通 RAG 技术在私有数据,如企业的专有研究、商业文档表现非常差,而 GraphRAG 则基于前置的知识图谱、社区分层和语义总结以及图机器学习技术可以大幅度提供此类场景的性能。微软在其博客上介绍说,他们在大量数据集上进行了测试,在全面性、多样性、赋权性方面,结果显示 GraphRAG 都优于朴素 RAG(70~80% 获胜率)。
Crawlee 是一个网页抓取和浏览器自动化的 Python 库,可用来提取 AI、LLM、RAG 或 GPT 的数据。
PDF-Extract-Kit 是一个专门用于提取PDF文件中高质量内容的工具包。它通过多个组件实现对PDF文档的深度解析,包括版面检测、公式检测、公式识别和光学字符识别。
5、MinerU
Magic-PDF 是一款将 PDF 转化为 Markdown 格式的工具,它是基于 PDF-Extract-Kit 库实现的。

6、mem0
增强 LLM 上下文连续性的 Python 库。该项目能为多种主流的大型语言模型提供记忆层,它支持保存用户与 LLM 交互时的会话和上下文,并能实时动态更新和调整,从而增强 AI 的个性化。适用于学习助手、医疗助理和虚拟伴侣等需要长期记忆的个性化 LLM 应用。
7、Storm
斯坦福开源的一个基于LLM的AI搜索开源框架,整合搜索、RAG知识库,实现AI辅助编写论文。Storm将生成带引用的长篇文章分为两个步骤:1)写作前阶段:系统进行基于互联网的调研,收集参考资料并生成提纲。2)写作阶段:系统利用提纲和参考文献生成带有引文的全文文章。
8、jurigged
这是一个专为 Python 提供热重载功能的库,它支持在程序运行时修改和更新 Python 代码,无需重启程序。
PptxGenJS 是一个用于在网页上生成 PPT 的 JavaScript 库,具备实现动态生成演示文稿的功能。
在Python应用中集成语义检查的能力,从而帮助用户提高他们的写作质量和准确性。
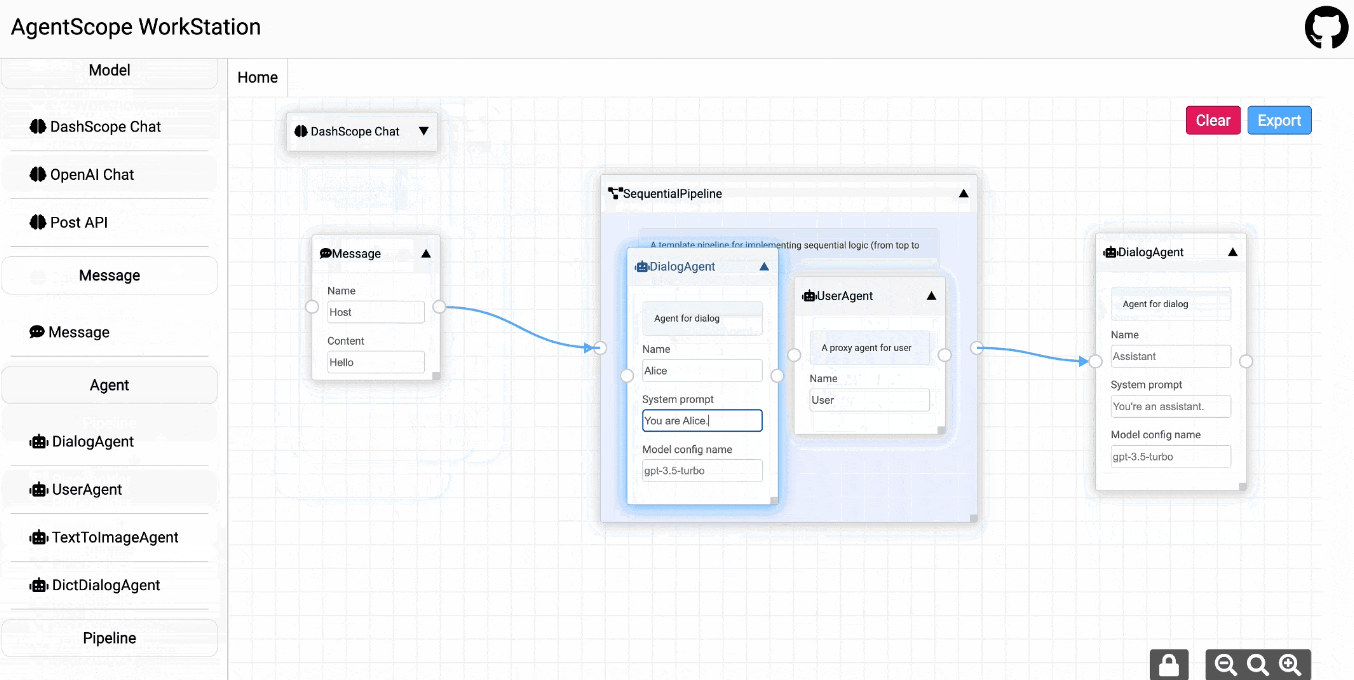
11、AgentScope
AgentScope是一款全新的Multi-Agent框架,旨在赋予开发人员使用大模型轻松构建多智能体应用的能力。
12、EchoMimic
EchoMimic是阿里开源的基于音频驱动的肖像动画生成工具,通过可编辑的特征点条件生成逼真、自然的动画,用户可以根据自己的需求调整动画细节,可用于虚拟主播、视频编辑等。
13、video2x
Video2X是一款使用Python编写的无损视频/GIF/图像放大工具,它基于Waifu2X、Anime4K、SRMD、RealSR等技术实现。能够从低分辨率输入中恢复细节并放大视频、GIF和图像,支持GIF转视频和视频转GIF的批量处理,无损提升画质且不出现锯齿或像素丢失。
14、streamlit
Streamlit是一个用于快速创建数据应用程序的Python库。它提供了一种简单而直观的方式来构建交互式Web应用,这些应用可以展示数据可视化、接受用户输入,并实时更新显示结果。使用Streamlit,你无需具备Web开发或前端开发经验,只需使用Python就能创建出功能强大的AI应用程序。
15、FastAPI
FastAPI是一个现代、快速的 Web 框架,用于构建基于 Python 的 API。它基于 Starlette 和 Pydantic 库构建而成,提供了强大的功能和高效的性能。它的性能非常高,可与NodeJS和Go媲美,是目前最快的Python框架之一。
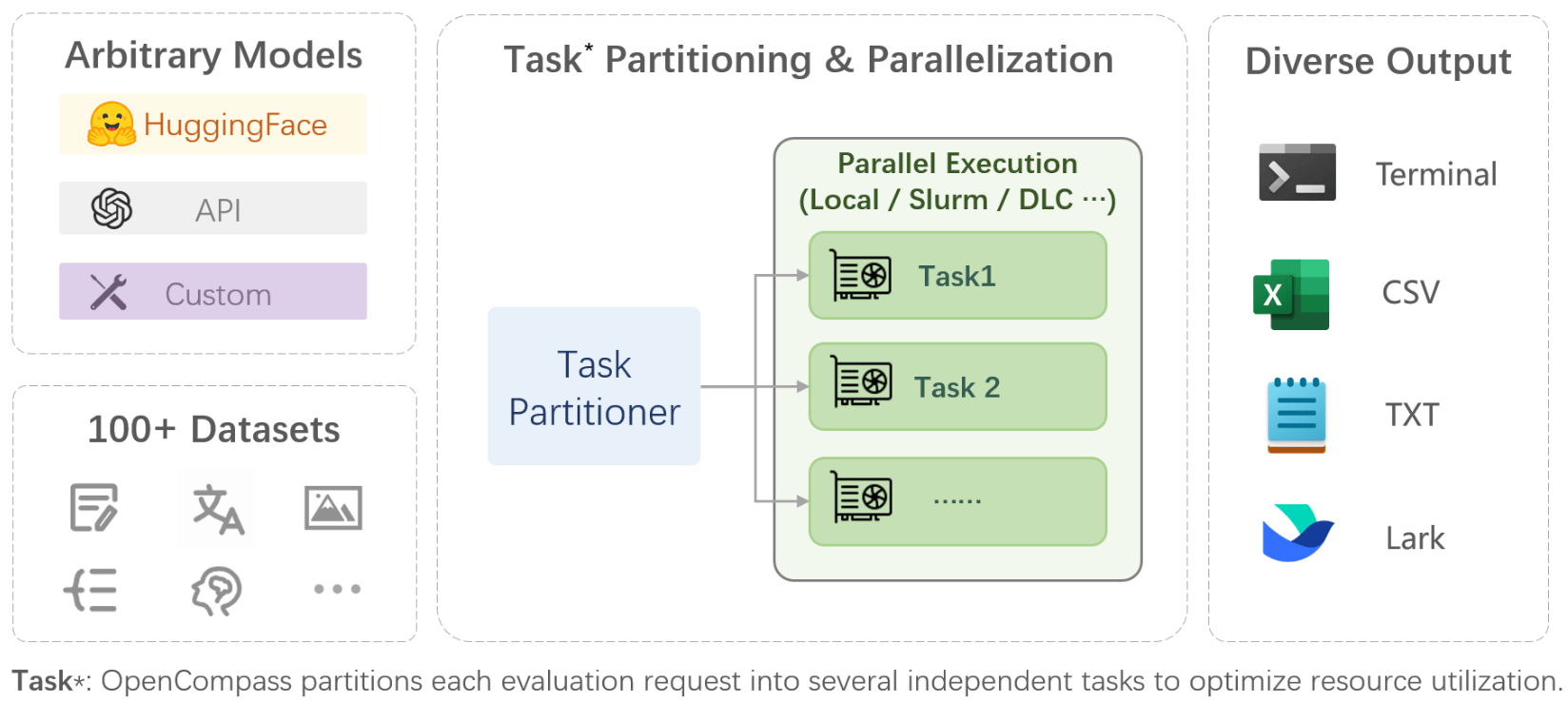
16、OpenCompass
OpenCompass 是面向大模型评测的一站式平台。其主要特点包括:开源可复现、全面的能力维度、丰富的模型支持、分布式高效评测、多样化评测范式、灵活化拓展。
17、xyflow
用于构建基于节点的编辑器和交互式图表,支持 React 和 Svelte 框架。它开箱即用且高度可定制,适用于开发工作流和流程图等场景。
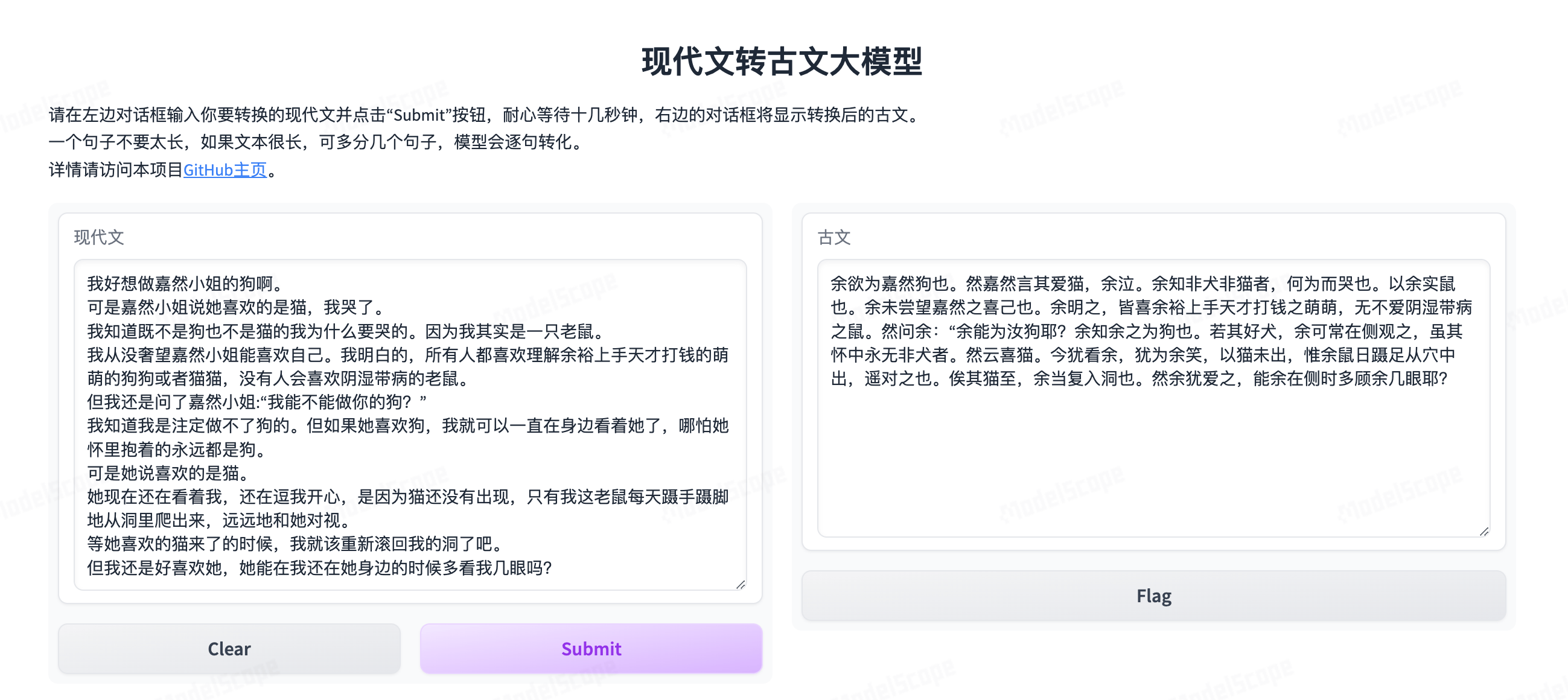
18、ancient_text_generation_LLM
输入现代汉语句子,生成古汉语风格的句子。在线体验
19、FinGPT
FinGPT是一个开源的金融领域大型语言模型,旨在提供一个适用于金融数据的训练和微调平台。它通过最新的调整方法如LoRA增强模型的适应性和准确性,支持多任务处理,如情感分析和市场数据分析。
20、BCEmbedding
BCEmbedding是由网易有道开发的中英双语和跨语种语义表征算法模型库,其中包含 EmbeddingModel 和 RerankerModel 两类基础模型。EmbeddingModel 专门用于生成语义向量,在语义搜索和问答中起着关键作用,而 RerankerModel 擅长优化语义搜索结果和语义相关顺序精排。
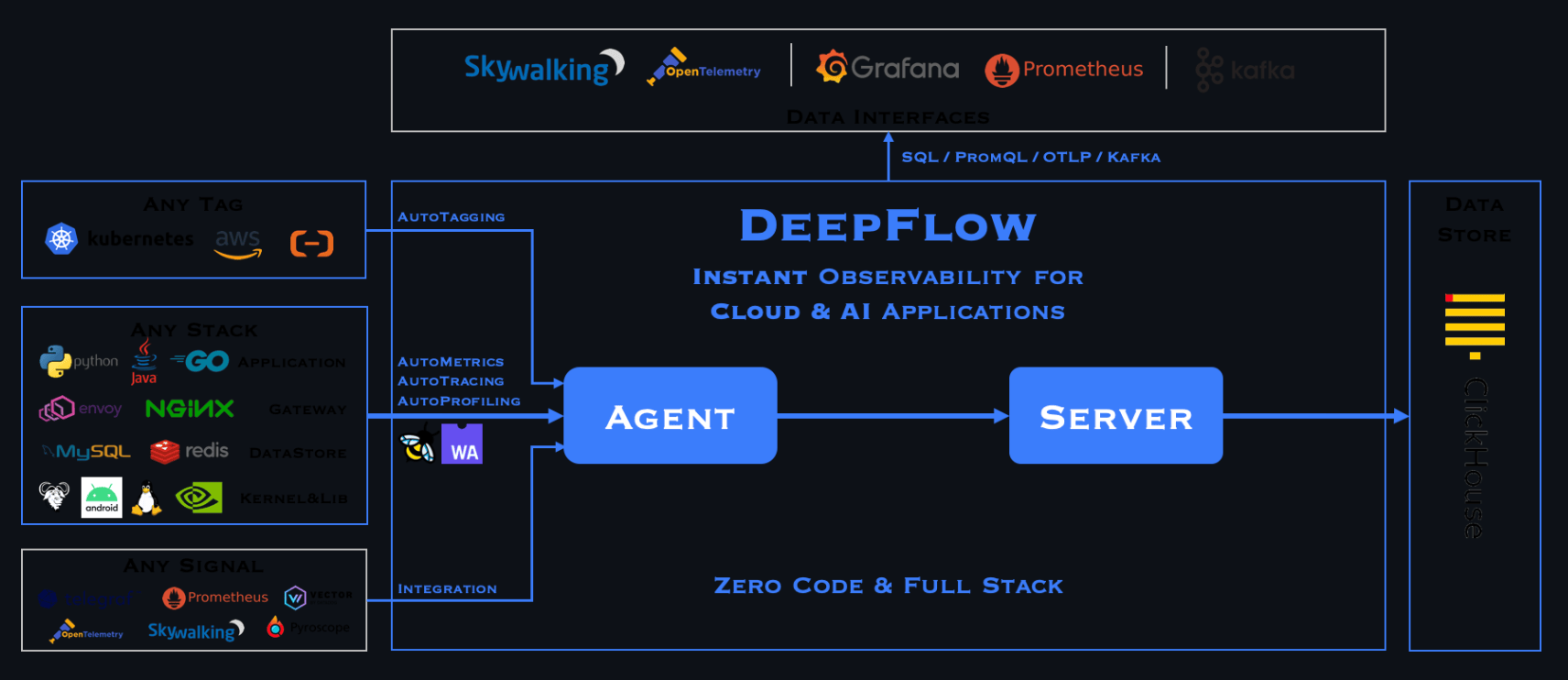
21、DeepFlow
DeepFlow 是一款为云原生开发者实现可观测性而量身打造的全栈、全链路、高性能数据引擎。帮助解决云及云原生应用诊断难的核心痛点,通过细粒度、多维度的可观测性数据打通各部门之间的协作壁垒,为企业数字化、智能化转型提供高度自动化的可观测数据底座。
22、bark
Bark 是由 Suno 创建的基于转换器的文本到音频模型。它可以生成高度逼真的多语言语音以及其他音频--包括音乐、背景噪音和简单的音效。该模型还可以产生非语言交流,如大笑、叹息和哭泣。
23、fish-speech
Fish Speech 是一个全新文本转语音(TTS)解决方案。该模型基于约15万小时的中、日、英三语数据进行训练,尤其对中文的支持非常出色。它能高效生成中文、日语和英语的语音,语言处理能力接近人类水平,且具备丰富多样的声音表现。
24、zerox
一个 JS/Python 库,使用 OpenAI 对 PDF 文件进行文字识别。

25、graphhopper
该项目是用 Java 开发的高性能路径规划引擎,能够快速计算两点或多点之间的距离。它支持 Dijkstra、A* 和收缩层级(CH)等算法,可以作为 Java 库或 Web 服务使用。基于 OpenStreetMap 地图数据,可实现汽车、自行车、步行等多种交通方式的路线规划和导航服务。
26、spring-ai
这是由 Spring 官方开源的用于简化包含 AI 功能的应用开发的 Java 框架,它可以轻松接入 OpenAI、Microsoft、Amazon、Google 和 Huggingface 等主流模型供应商,以及聊天、文本生成图像的模型类型,支持提示工程、AI 模型转 POJO 对象、矢量数据库、RAG(检索增强生成)等有助于开发 AI 应用的功能。
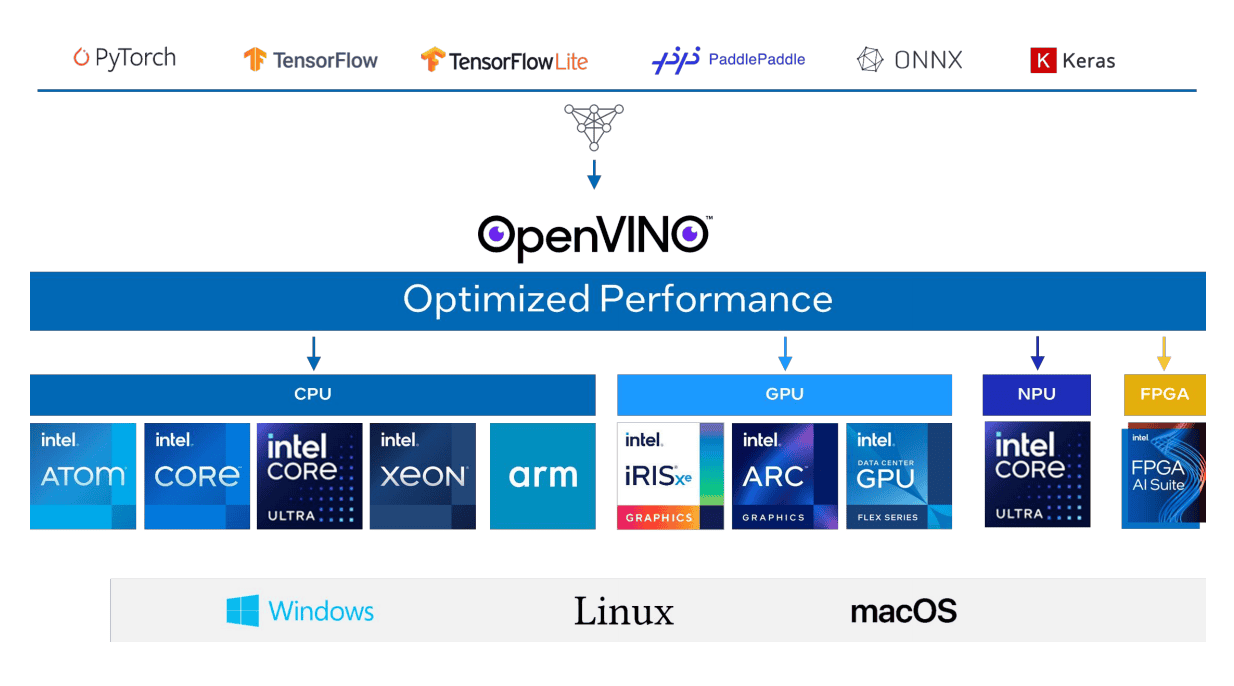
27、openvino
该项目是英特尔开源的工具库,旨在加速和优化深度学习模型部署。它能帮助开发者将训练好的模型部署到多种硬件平台,支持 TensorFlow、PyTorch 和 ONNX 等深度学习框架。
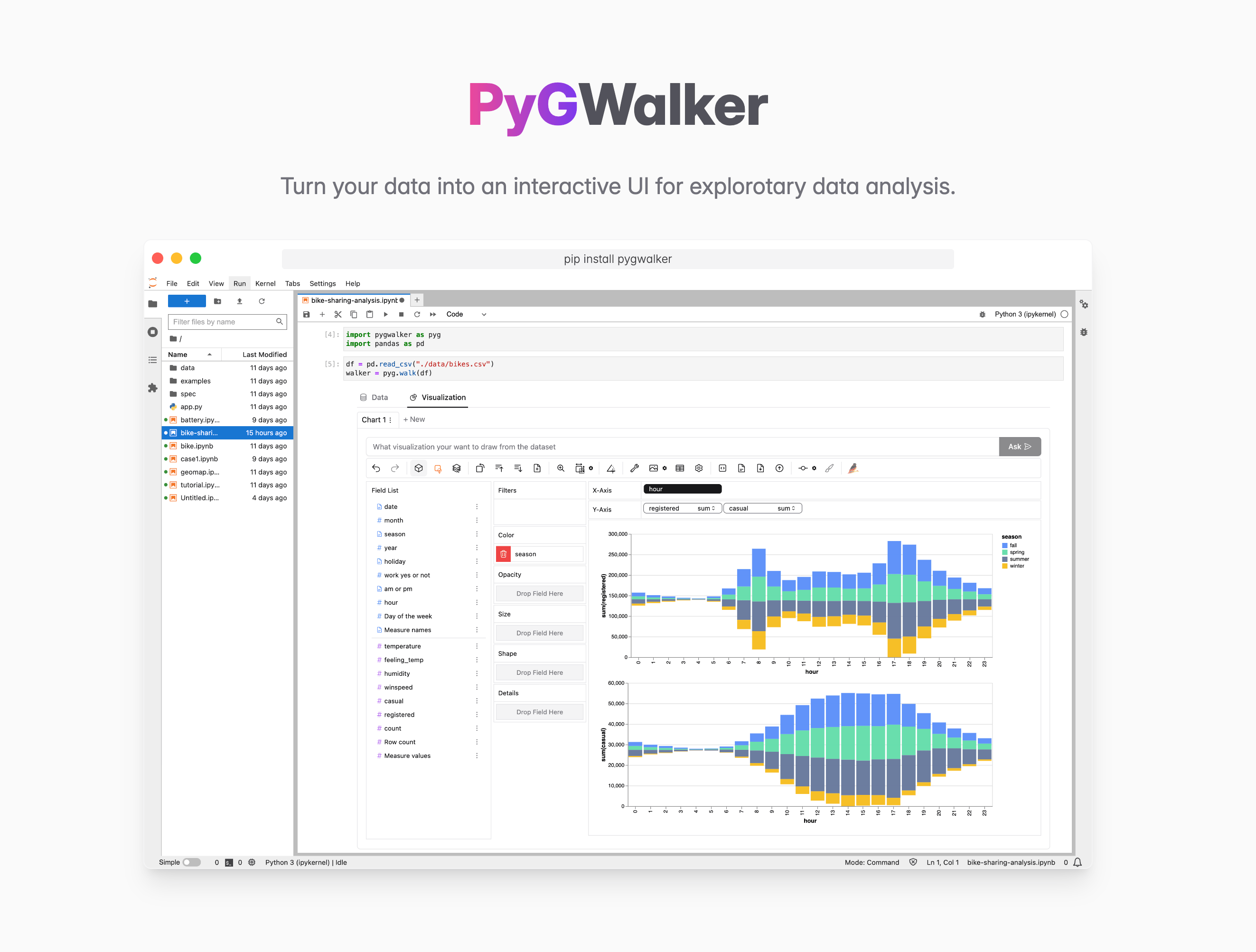
28、PyGWalker
一行代码将数据集转化为交互式可视化分析工具,可将你的 pandas 数据转换为可交互的 UI,以进行可视化分析。
五、工具软件
1、SunoAI(免费)
Suno AI是一款基于人工智能的音乐创作工具,它可以帮助用户轻松地创作出各种风格的音乐作品。通过使用先进的深度学习技术,Sono AI能够生成具有高质量音频输出和立体声效果的歌曲,效果非常惊艳。
2、EasyVideoTrans(开源)
一个开源工具,能够快速的将英文视频转成中文视频,部署需要GPU环境。
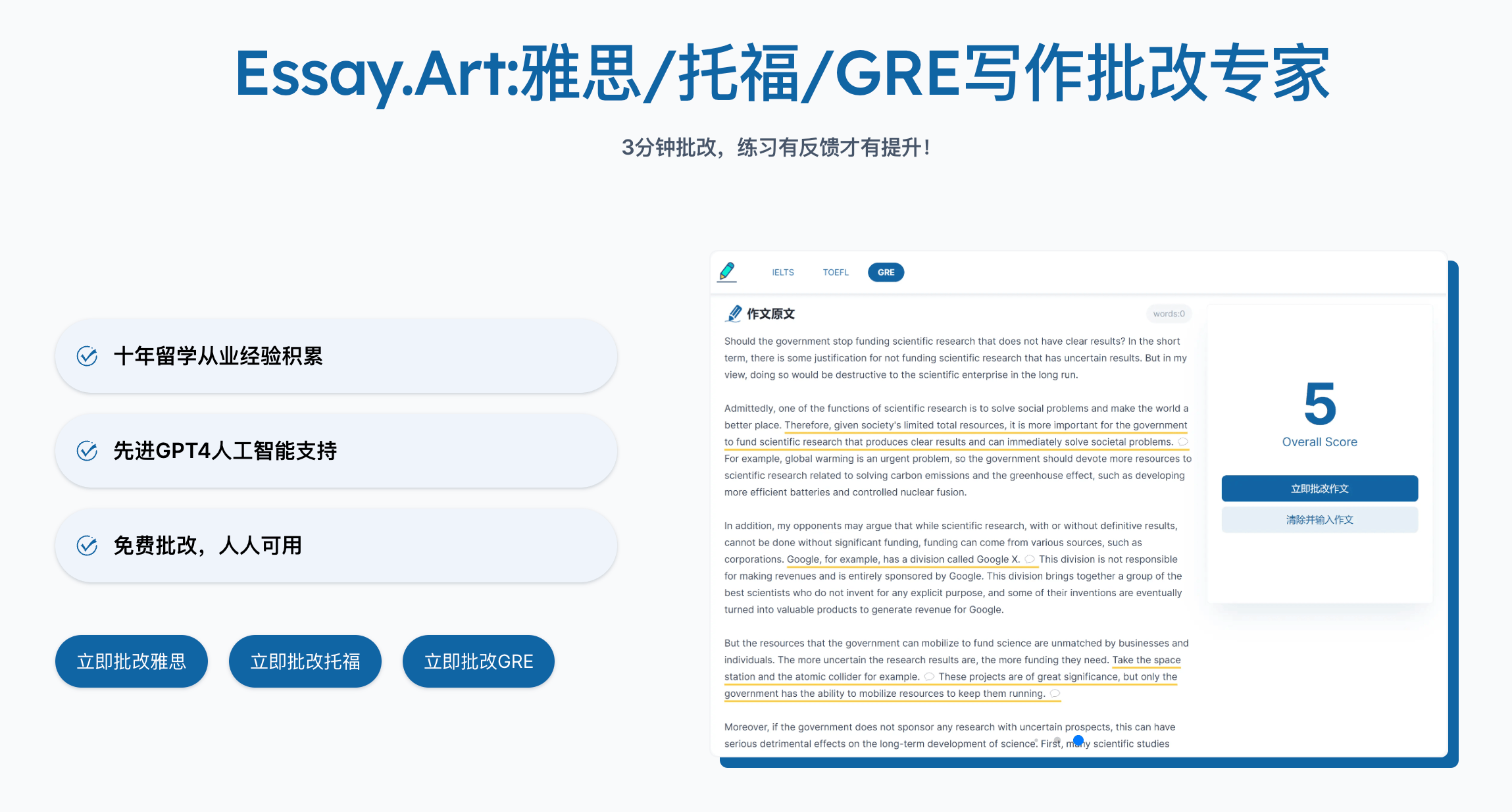
3、Essay.Art(免费)
基于 GPT4 批改雅思和托福作文的在线工具。
4、Win11Debloat(开源)
Win11Debloat是一个旨在通过删除 Windows 10 和 Windows 11 中不必要的系统组件、应用程序和服务来优化系统性能并提高用户体验的开源项目。
5、WebUI(开源)
一个跨平台的桌面应用的打包程序,允许你直接将浏览器作为桌面应用的前端,比 Electron 要轻量化很多,同时又避免使用 WebView。
6、penpot(开源)
用于设计和代码协作的开源原型设计工具,可以私有化部署。
7、Docker-Proxy(开源)
自建Docker镜像加速服务,基于官方Docker Registry 一键部署Docker、K8S、Quay、Ghcr、Mcr等镜像加速管理服务。
8、LabelLLM(开源)
LabelLLM是一个开源的数据标注平台,致力于优化对于大型语言模型开发不可或缺的数据标注过程。LabelLLM的设计理念旨在成为独立开发者和中小型研究团队提高标注效率的有力工具。
9、Lean(开源)
基于 C# 的量化交易引擎。这是一款采用 C# 编写的开源、经过实战考验的量化交易引擎。支持使用 Python3 或 C# 编写交易算法,兼容 Windows、Linux 和 macOS 平台,适用于量化交易策略研究、回测和实盘交易等场景。
10、subtitleedit(开源)
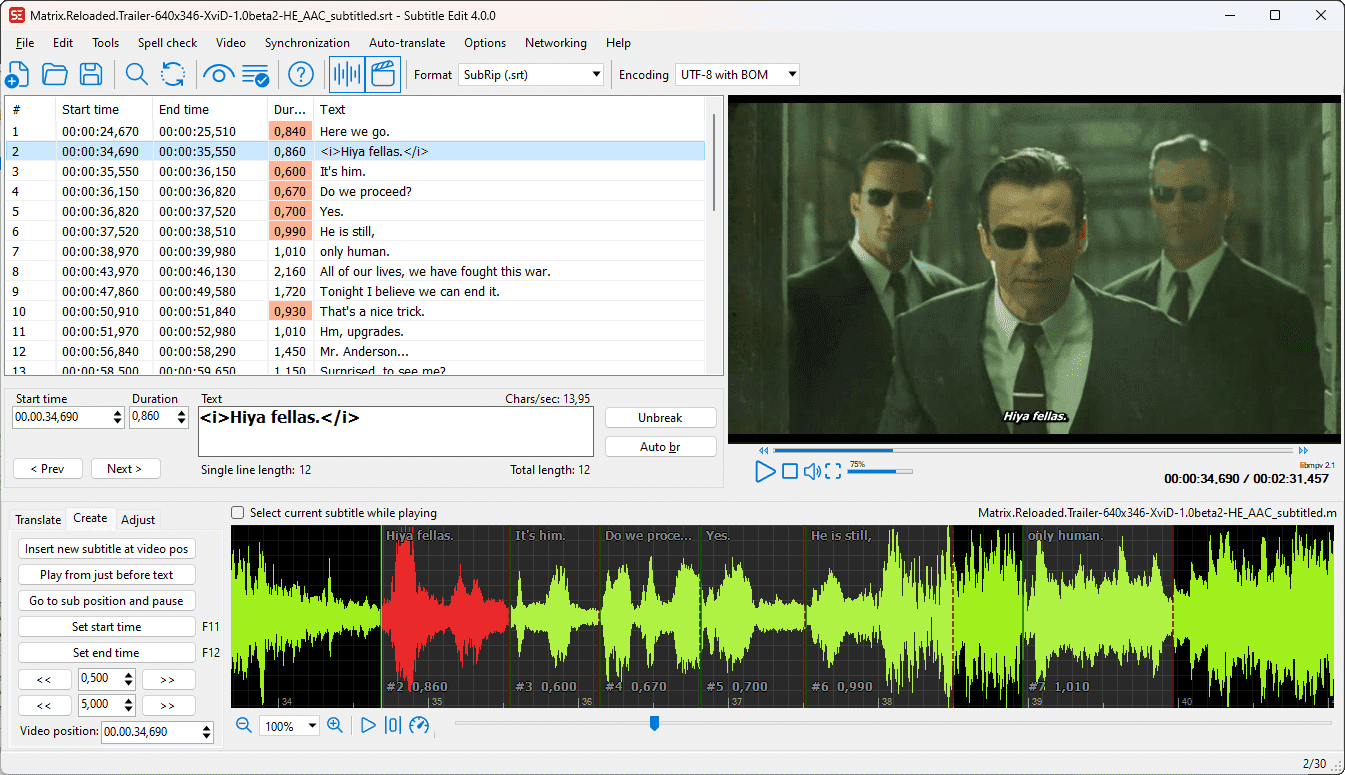
开源的视频字幕编辑工具。这是一款适用于 Windows 的免费视频字幕编辑器。它开箱即用且功能强大,支持创建、调整、同步和翻录字幕,还提供了自动翻译、字幕格式转换和语音识别等功能。
11、buildg(开源)
该项目是基于 BuildKit 的交互式调试 Dockerfile 的工具,支持设置断点、单步执行和非 root 模式,可以在 VSCode 等编辑器中使用。
12、Typebot(开源)
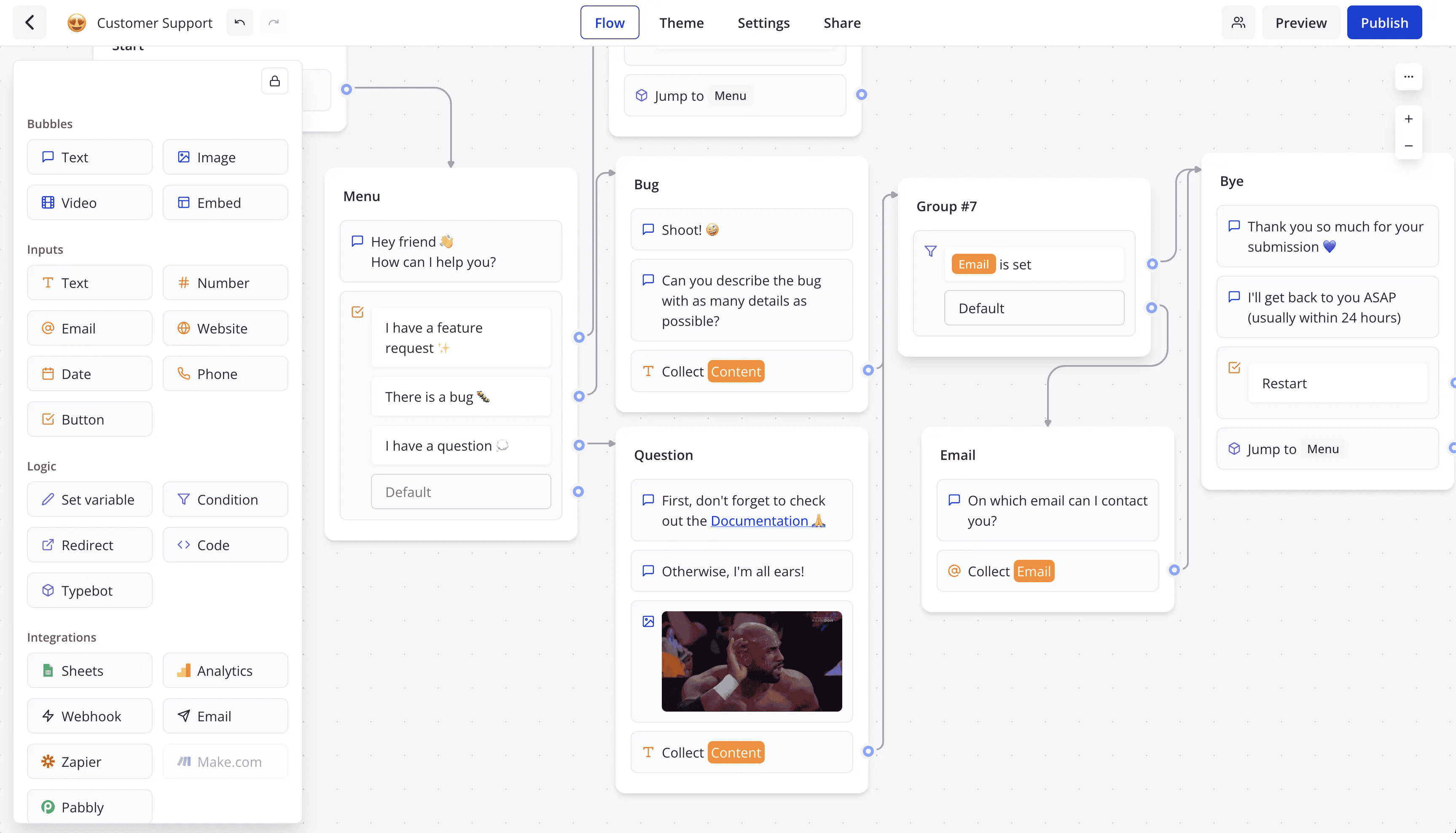
自托管的聊天机器人构建器。该项目通过可视化的拖拽界面,让用户能够轻松创建高级聊天机器人,并将其嵌入网站中。它提供了 30 多种聊天构建块,支持自托管、分析工具、自定义域名和品牌定制等功能,适用于在线客服和销售支持等场景。
13、PlayCover(开源)
该项目是专为 Apple Silicon Mac 设备设计,用于运行 iOS 应用和游戏的工具。它通过模拟 iPad 环境和键盘映射功能,让用户可以在 Mac 电脑上玩 iOS 游戏,需自行下载 IPA 文件,适用于 macOS 12.0 或更高版本。
14、GScan(开源)
旨在为安全应急响应人员对Linux主机排查时提供便利,实现主机侧Checklist的自动全面化检测,根据检测结果自动数据聚合,进行黑客攻击路径溯源。
15、frpc-desktop(开源)
内网穿透工具 frp 的跨平台桌面客户端。
16、ShareDrop(开源)
一款受 Apple AirDrop 启发的开源 Web 应用,利用 WebRTC 技术实现了安全的点对点(P2P)文件传输。用户无需上传文件至服务器或安装客户端,只需打开网页,即可在局域网、互联网和跨设备间轻松、安全地共享文件。
17、Watchy(开源)
该项目是采用 ESP32-PICO-D4 和电子墨水屏制作的一款智能手表,支持日历、闹钟、步数、手势检测,以及 WiFi 和蓝牙等功能。

18、Zoraxy(开源)
一个主要用来反向代理的 Web 服务器软件,特点是提供图形界面进行配置,对新手很友好。
19、magic-wormhole(开源)
Magic Wormhole 是一个用于在两台计算机之间安全传输文件的工具。它使用了一系列现代加密技术来保障传输的安全性,包括公钥加密、临时密钥交换等。它不依赖于中心化的服务器或第三方服务,因此能够确保传输的隐私和安全性。
20、austin(开源)
这是一款专为 Python 程序设计的性能分析工具,无需修改代码即可轻松定位 Python 程序的性能瓶颈和内存使用情况。它是采用 C 语言编写的 CPython 帧堆栈采样器,具有体积小、运行速度快、零代码侵入等特点。
21、Deep-Live-Cam(开源)
Deep Live Cam 是一款开源工具,利用 AI 算法实现实时换脸和一键式视频深度伪造,用户只需一张源图像即可在视频或直播中替换人脸。该工具通过自动检测和对齐,生成无缝的换脸效果,同时内置检查机制以确保道德使用。
22、PDFQFZ(开源)
该项目是用于在 PDF 文件上加盖骑缝章的工具,适用于 Windows 平台。使用时可以指定目录,对多个 PDF 文件进行批量处理,支持预览、调整印章大小和位置等功能。
23、JPlag(开源)
用于检测源代码相似度的工具,支持 Java、C/C++、Python、JavaScript 等多种编程语言,适用于识别编程作业中的抄袭行为等场景。
24、MooTool(开源)
这是一款用 Java 开发的开发者常用工具的桌面应用,支持 Windows、macOS 和 Linux 系统。它为开发者提供了多种实用工具,如文本转换、时间处理、JSON 格式化和正则匹配测试等。
25、Reactive-Resume(开源)
一个免费、开源、无广告的在线简历制作平台,内置 12 款专业的简历模板,支持多语言、PDF 导出和 OpenAI 集成等功能。
26、NotchDrop(开源)
一个开源工具,将 MacBook 刘海变成一个文件传输和暂存区域。
27、Pearcleaner(开源)
这是一款免费开源的 Mac 应用清理工具,能够彻底卸载应用并清理残留文件。它采用 SwiftUI 开发,提供了简单易用的界面,支持右键卸载、迷你模式和 Homebrew 清理等功能。

27、deskreen(开源)
利用 WebRTC 技术将电脑屏幕通过 WiFi 镜像到具有 Web 浏览器的设备屏幕上,实现屏幕共享功能,使其成为电脑的辅助显示器。
28、kotaemon(开源)
一个开源的本地工具,可以指定 AI 模型,与添加的文档聊天。

29、watson.ai(开源)
一个开源的 Mac/Windows 桌面程序,通过系统麦克风,录制远程会议的音频,然后用 AI 生成会议记录和摘要。
30、Linly-Dubbing(开源)
AI 视频配音的开源工具,自动将外语视频改成中文配音。
31、Dokku(开源)
Dokku 是一个基于 Docker 的轻量级 PaaS 实现,旨在帮助用户构建和管理应用的生命周期。 它主要解决了用户在服务器上部署和管理应用的复杂性,使其过程更加简便和自动化。
32、HivisionIDPhotos(开源)
HivisionIDPhoto 旨在通过智能算法简化证件照生成流程。该项目利用完善的模型工作流程,能够识别多种拍照场景,进行精准抠图并自动生成标准证件照,仅使用 CPU 即可快速完成抠图任务。
33、文颜(开源)
一个 Mac 桌面软件,可以将 Markdown 文档转换成公众号、知乎、今日头条等格式。
34、Nginx UI(开源)
该项目是用 Go+Vue.js 构建的 Nginx 在线管理平台,它开箱即用、功能丰富,支持流量统计、在线查看 Nginx 日志、编辑 Nginx 配置文件、自动检查和重载配置文件等功能。
35、watchtower(开源)
该项目能够自动监测并更新正在运行的 Docker 容器,定期检查并拉取 Docker Hub 或私有镜像仓库中的最新镜像版本,并自动重启容器。适用于开发、测试和个人使用场景,但不建议在生产环境中使用。
36、shadcn-ui(开源)
这是一款由 Vercel 开源、基于 React 开发的 UI 组件集合,包括仪表板、卡片、模型对话、表单、登录等组件,拿来即用。通过 CLI 引入组件后,将得到该组件的源码,可随意修改和定制。
37、uv(开源)
基于 Rust 开发的下一代 Python 包管理工具,可用于替代传统的 Python 包和环境管理工具。它兼容 pip、pip-tools 和 virtualenv 命令,速度比这些工具快 10-100 倍,并通过全局依赖缓存节省更多的硬盘空间,开箱即用支持 Windows、Linux 和 macOS 系统。
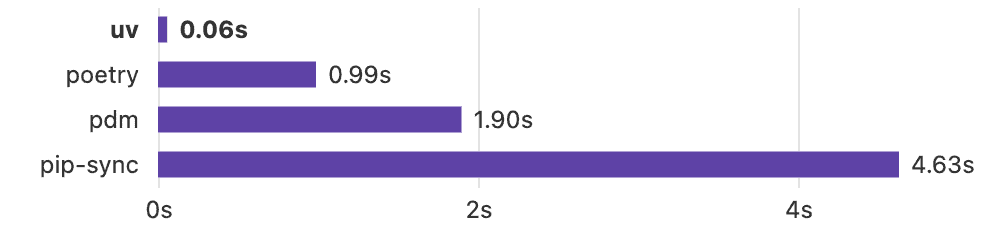
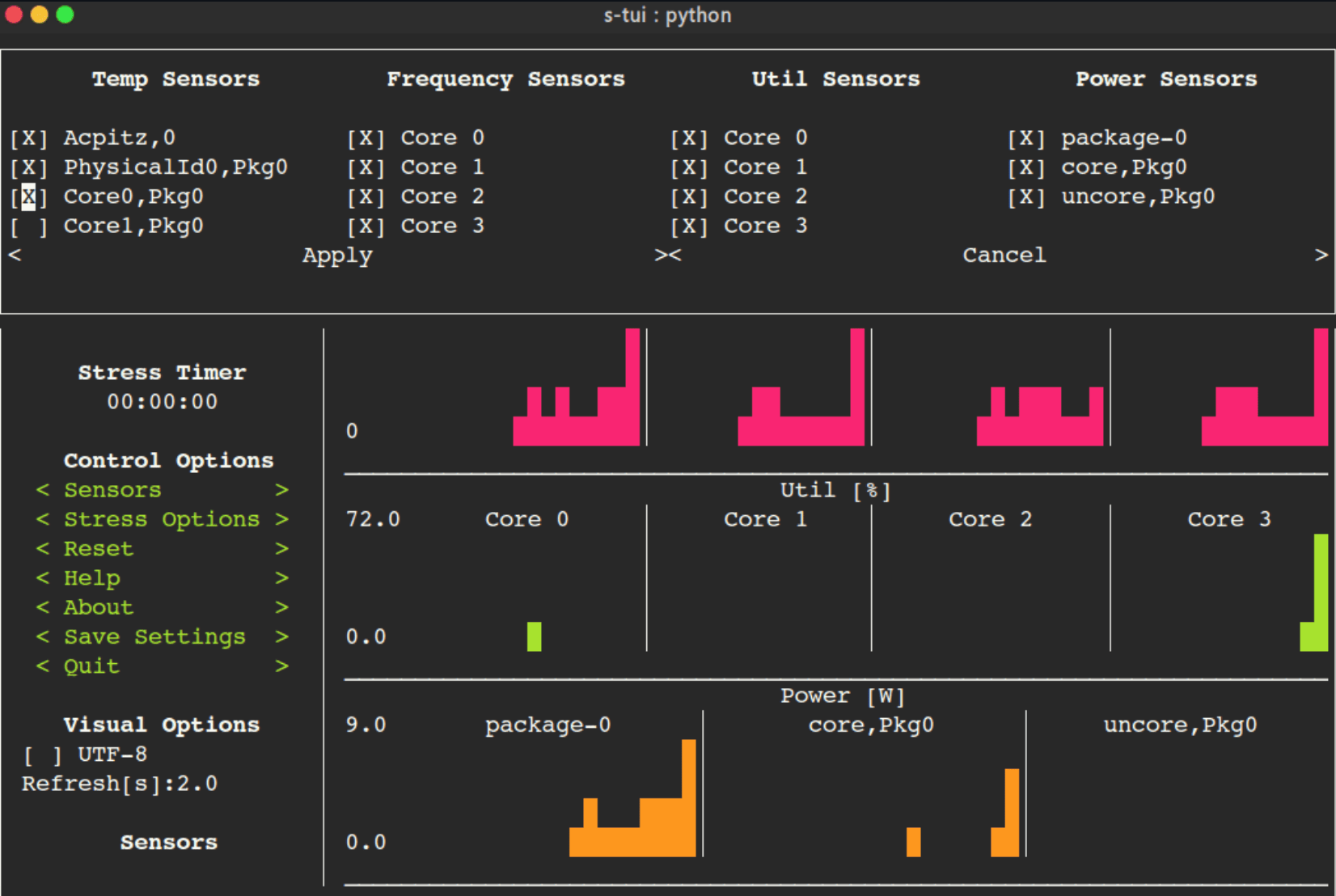
38、s-tui(开源)
基于终端的CPU监控和压测工具,可在终端中以图形方式实时显示CPU温度、频率、功率和利用率等信息。它还支持安装FIRESTARTER等工具,对CPU进行压力测试。
六、学习资源
1、LLM-Powered-RAG-System(英文)
一个收集性质的清单,列举了与RAG技术相关的框架、应用程序。
2、metahuman_overview(中文)
一个收集性质的清单,列举了与数字人有关的技术。主要包括形象、声音和对话能力几方面,主要交互方式为直接与数字人进行对话。
3、如果你是CPU(英文)
一本英文科普书籍,介绍计算机底层知识,免费阅读。

4、awesome-chatgpt-prompts-zh(中文)
ChatGPT中文调教指南,里面包含各种场景的Prompt。
5、RAG_Techniques(英文)
该项目提供了 20 多种先进的 RAG 技术教程,包含实现指南和示例代码,并定期更新。内容涵盖检索查询、上下文增强、融合检索、分层索引、上下文压缩、知识图谱整合等多种 RAG 技术。
6、LLM 大模型训练之路(中文)
一篇关于大模型训练的系列文章,包含训练数据、模型训练、模型评测的完整流程。
七、生活经验
1、德雷克海峡
德雷克海峡(Drake Passage)位于南美洲与南极洲之间,太平洋和大西洋在这里交汇。南极大陆的干冷空气与美洲大陆湿暖的气流之间存在气压差,使得这里成为地球上最危险的海域,终年有八级以上大风,狂浪肆虐,无数水手丧生于此。海峡一侧就是南美洲最南端的合恩角,在这里耸立着一块纪念碑。上面写着,纪念在此处死于海难的至少 10,000 名水手。

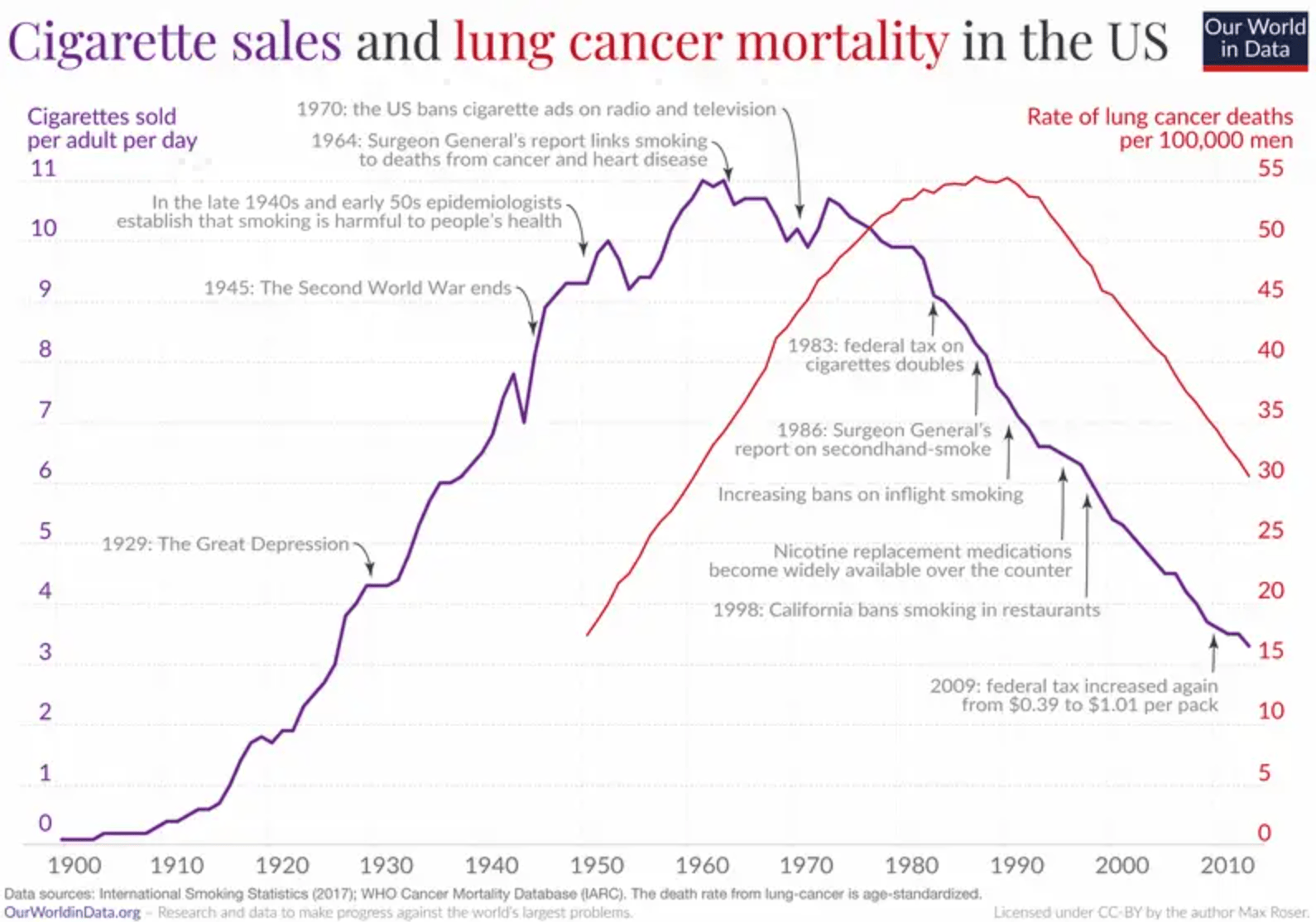
下图有两根曲线,紫色是美国历年的卷烟销售数量,红色是肺癌死亡率。可以看到,两者形状一模一样,表明是强相关,肺癌死亡率滞后卷烟销售量大约25年~30年。1964年,美国卷烟销售达到顶峰,然后逐年下降;1990年代初,肺癌死亡率达到顶峰,然后逐年下降。
3、隐性知识是危险的
隐性知识又称为“部落知识”,指的是有些知识没有文档,只掌握在团队成员的头脑里面。如果你想掌握这些知识,只有去询问团队成员。
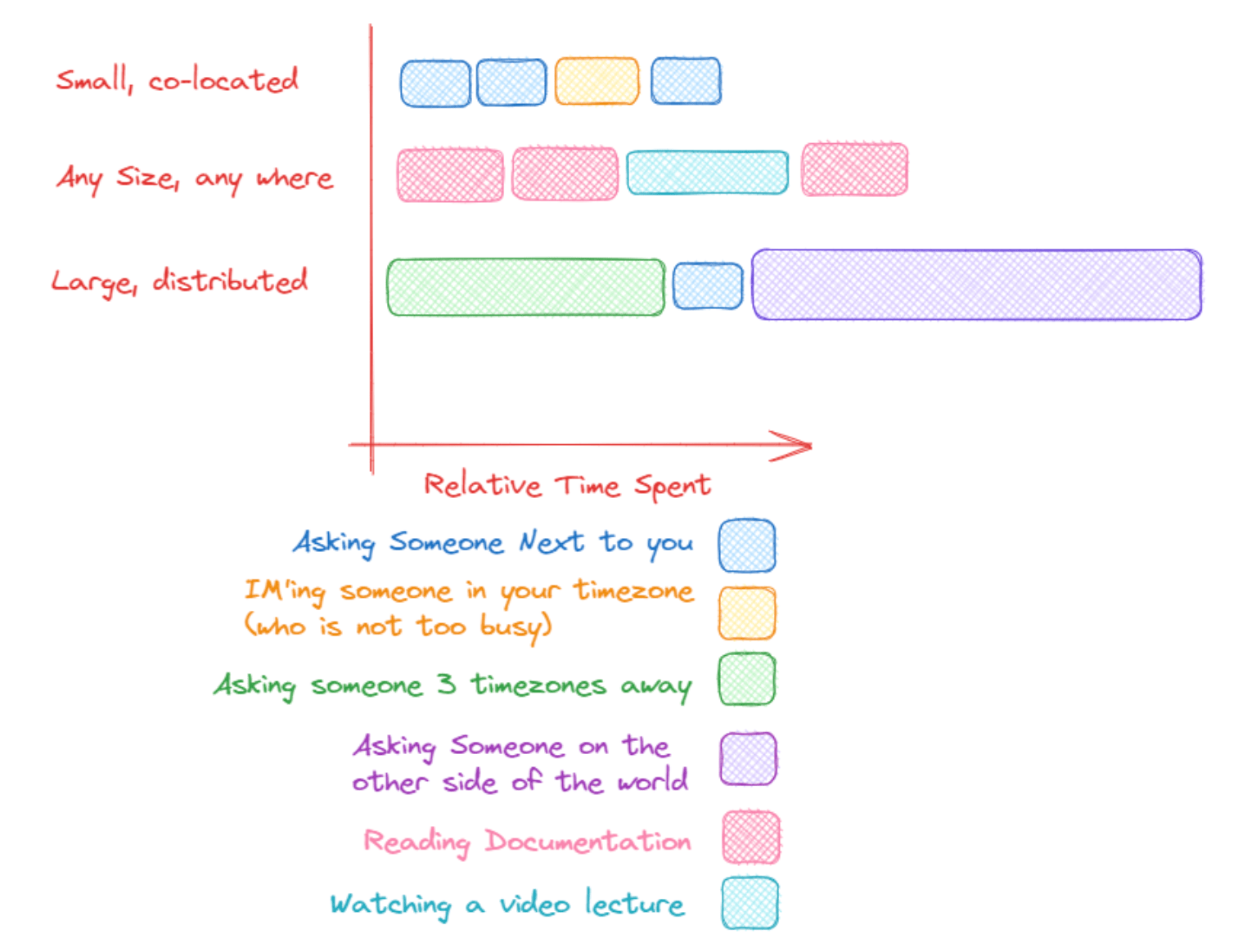
隐形知识的优点是,省去了文档成本,而且询问相关成员比自己阅读文档更快,当然前提是那位成员能够快速响应。隐形知识的缺点是,一旦团队扩大规模,它就会失败。对于掌握知识的团队成员来说,回答问题所占用的时间是一个拖累,影响了生产力,也拖慢了团队的开发速度。
随着团队规模的扩大和知识变得更加分散,你自己阅读文档和观看视频讲座,会比向他人寻求帮助更快速和方便。所以,团队越是大,就越要避免“隐形知识”,所有知识尽量文档化,让团队成员能够方便地查阅。
4、铅笔金属画
一位日本艺术家,专门用铅笔画出物品的金属光泽。

八、闲情逸趣
2024.9.12,OpenAI正式发布了OpenAI o1推理模型。o1模型的特殊之处在于其强大的推理能力,它擅长慢思考,在作出正式回答之前会进行“深思熟虑”,产生一个长长的思维链,并尝试通过不同的策略进行推理和反思,从而确保回答的质量和深度。因此,相比其他模型,o1模型“更大,更强,更慢,也更贵”。
Greg Brockman这样评价o1模型:
“可以这样理解,我们的模型进行系统 I 思考,而思维链则解锁了系统 II 思考。人们已经发现,提示模型「一步步思考」可以提升性能。但是通过试错来训练模型,从头到尾这样做,则更为可靠,并且——正如我们在围棋或 Dota 等游戏中所见——可以产生极其令人印象深刻的结果。”
这种强大推理能力使o1在多个行业中具有广泛的应用潜力,尤其是复杂的科学、数学和编程任务。同时,为了凸显o1模型在推理上的巨大进步,OpenAI也设计了一套完整的评估方案。测试结果令人振奋,在绝大多数需要深度思考和复杂推理的任务中,o1模型都要明显好于GPT-4o模型。
下图是在数学竞赛、编码竞赛和科学问答中的表现,o1要高出gpt4o一大截。

在其他学科领域,比如化学、物理、生物、经济学、逻辑学等领域,o1相比gpt4o也有显著提升。

目前,o1系列包含三款模型,OpenAI o1、OpenAI o1-preview和OpenAI o1-mini。OpenAI o1作为最高级的推理模型,暂不对外开放。OpenAI o1-preview,这个版本更注重深度推理处理,每周可以使用30次。OpenAI o1-mini,这个版本更高效、划算,适用于编码任务,每周可以使用50次。
从目前公开的消息得知,O1模型的核心是思维链(COT,chain of thought),但从实际表现来看,背后一定用到了其他更强大的推理模型,因为单独的COT无法让模型获得如此强的推理结果。
[1] 初级推理框架:COT、COT-SC和TOT
初级推理框架的核心主张,是将大型任务分解为更小、更易于管理的子目标,从而高效处理复杂任务。主要的子任务分解方式包括:思维链COT(Chain of thought)、自洽性思维链(COT-SC)、思维树TOT(Tree of thought)。
1)思维链COT
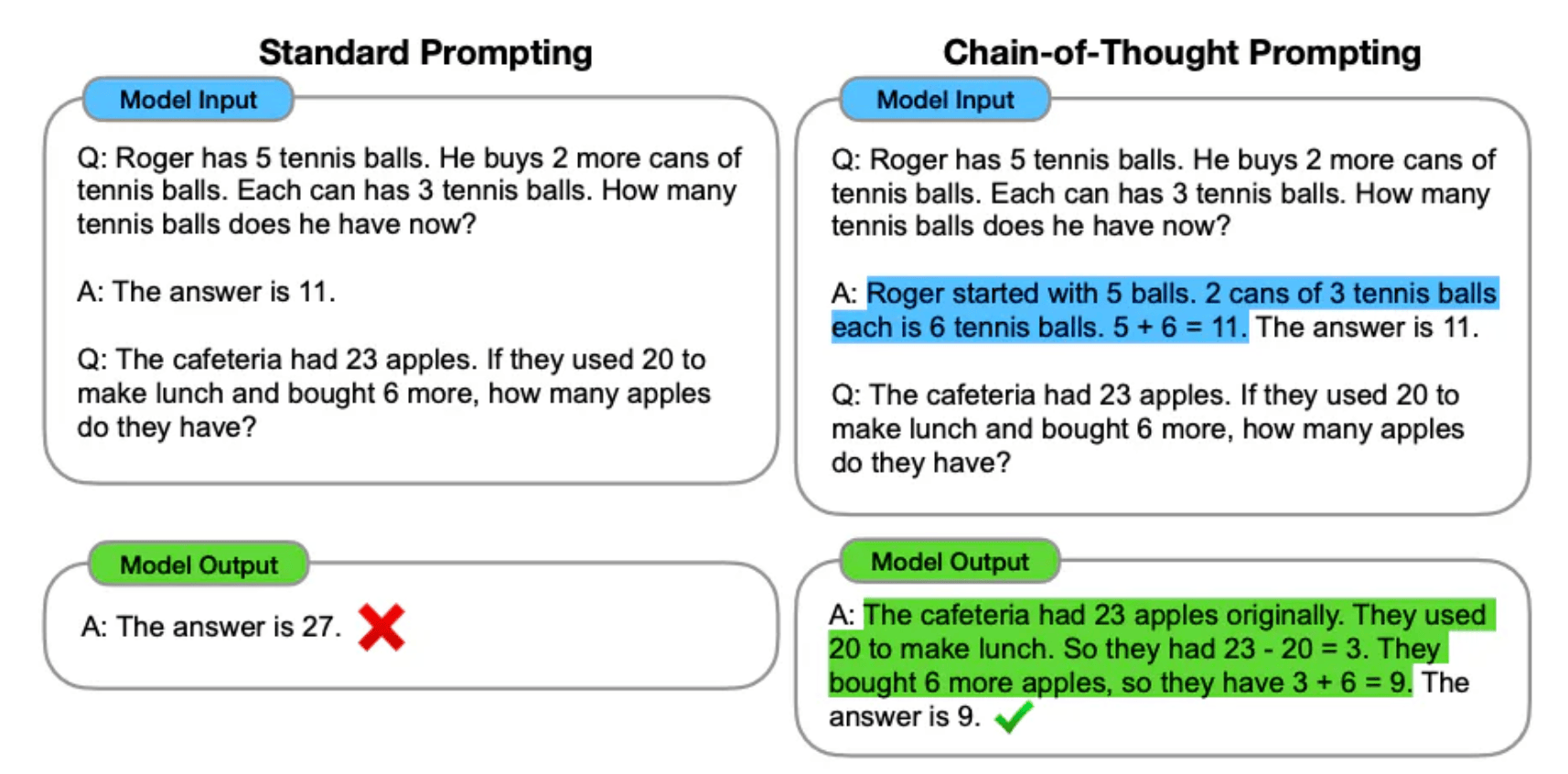
思维链COT的全称是Chain of Thought,当我们对LLM这样要求「think step by step」,会发现LLM会把问题分解成多个步骤,一步一步思考和解决,能使得输出的结果更加准确。这就是思维链,一种线性思维方式。
思维链适用的场景很多,包括各种推理任务,比如:数学问题、尝试推理、符号操作等。思维链方法的好处在于,不用对模型进行训练和微调。在下图的案例中,通过few-shot propmt,引导大模型先对问题进行拆解,再进行解答。其效果要远远好于直接询问。
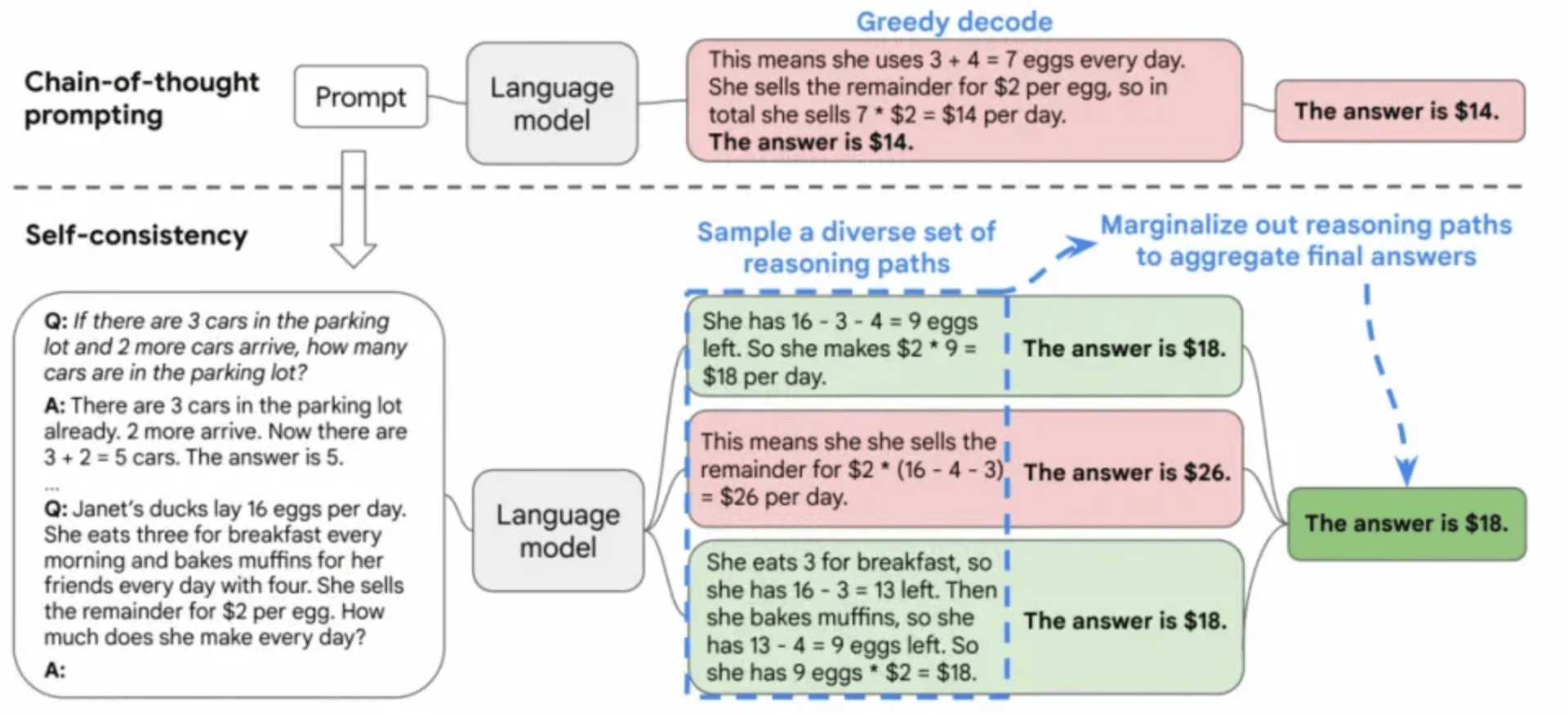
2)自洽性COT
所谓自洽性,是指一种为同一问题,生成多个不同的思维链,并对模型进行训练从中挑选出最合适的答案的方法。一个CoT出现错误的概率比较大,我们可以让大模型进行发散,尝试通过多种思路来解决问题,然后投票选择出最佳答案,这就是自洽性CoT。
这种方法特别适用于需要连续推理的复杂任务,例如思维链提示法。它在多个评估标准上显著提升了CoT提示的效果,如在GSM8K上提升了17.9%,在SVAMP上提升了11.0%,在AQuA上提升了12.2%。
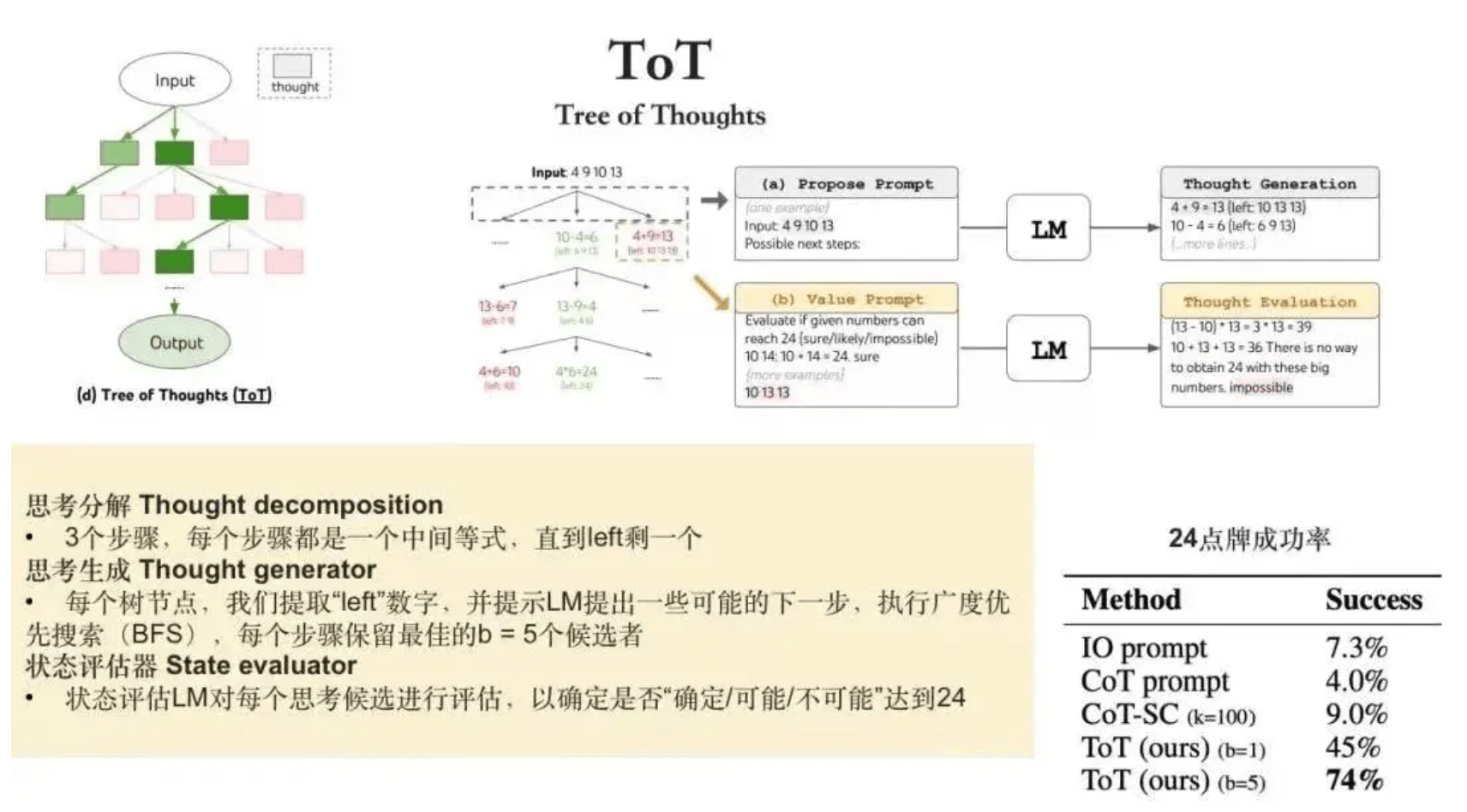
3)思维树TOT
思维树TOT是对思维链CoT的进一步扩展,在思维链的每一步,推理出多个分支,拓扑展开成一棵思维树。使用启发式方法评估每个推理分支对问题解决的贡献。选择搜索算法,使用广度优先搜索(BFS)或深度优先搜索(DFS)等算法来探索思维树,并进行前瞻和回溯。
[2] 中级推理框架:ReAct、Plan-and-Execute和Self Discover
初级推理框架的优势是简单,但缺点是缺少可控性,我们很难约束和控制大模型朝哪个方向推理。当推理方向存在错误时,也缺少纠错机制。因此,以ReAct、Plan-and-Execute和Self Discover为代表的推理框架,更主张约束大模型的推理方向,并根据环境反馈进行推理纠错。
1)ReAct
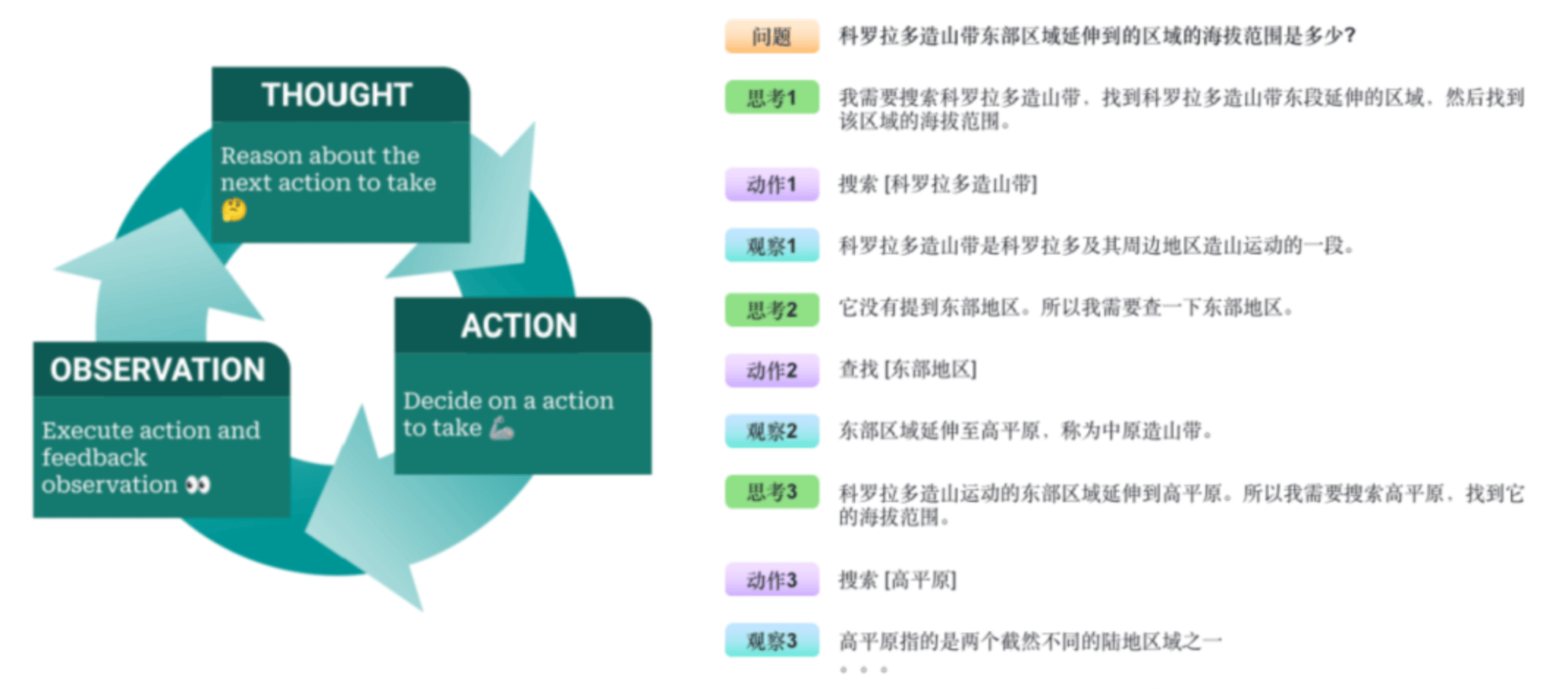
ReAct通过结合语言模型中的推理(reasoning)和行动(acting)来解决多样化的语言推理和决策任务,因此提供了一种更易于人类理解、诊断和控制的决策和推理过程。它的典型流程如下图所示,可以用一个有趣的循环来描述:思考(Thought)→ 行动(Action)→ 观察(Observation),简称TAO循环。
- 思考(Thought):面对一个问题,我们需要进行深入的思考。这个思考过程是关于如何定义问题、确定解决问题所需的关键信息和推理步骤。
- 行动(Action):确定了思考的方向后,接下来就是行动的时刻。根据我们的思考,采取相应的措施或执行特定的任务,以期望推动问题向解决的方向发展。
- 观察(Observation):行动之后,我们必须仔细观察结果。这一步是检验我们的行动是否有效,是否接近了问题的答案。
如果观察到的结果并不匹配我们预期的答案,那么就需要回到思考阶段,重新审视问题和行动计划。这样,我们就开始了新一轮的TAO循环,直到找到问题的解决方案。
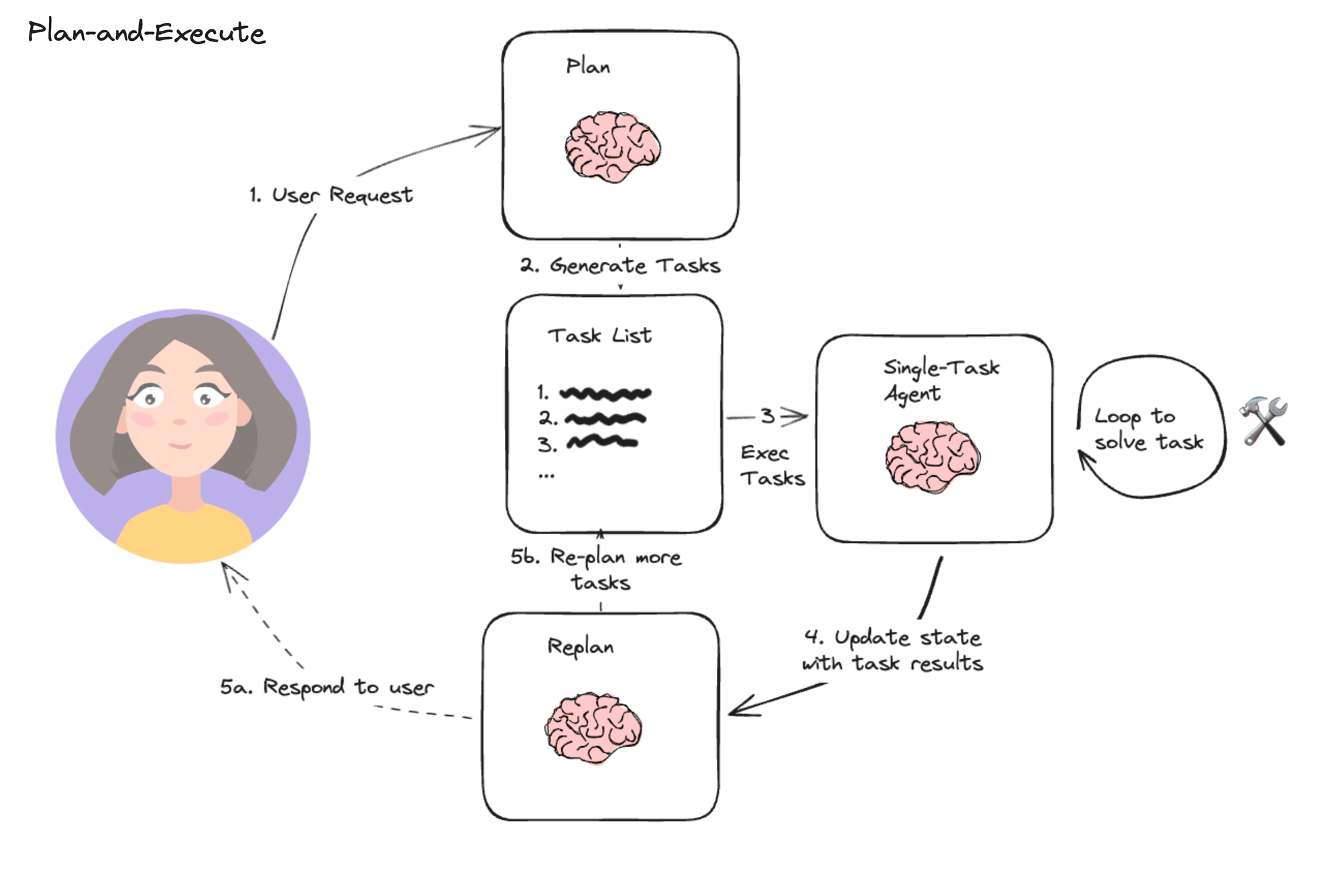
2)Plan and Execute
Plan and Execute 方法的本质是先计划再执行,即先把用户的问题分解成一个个的子任务,然后再执行各个子任务,并根据执行情况调整计划。它相比ReAct,最大的不同就是加入了Plan和Replan机制,其架构上包含规划器、执行器和重规划器:
- 规划器Planner负责让 LLM 生成一个多步计划来完成一个大任务,在实际运行中,Planner负责第一次生成计划;
- 执行器接收规划中的步骤,并调用一个或多个工具来完成该任务;
- 重规划器Replanner负责根据实际的执行情况和信息反馈来调整计划。
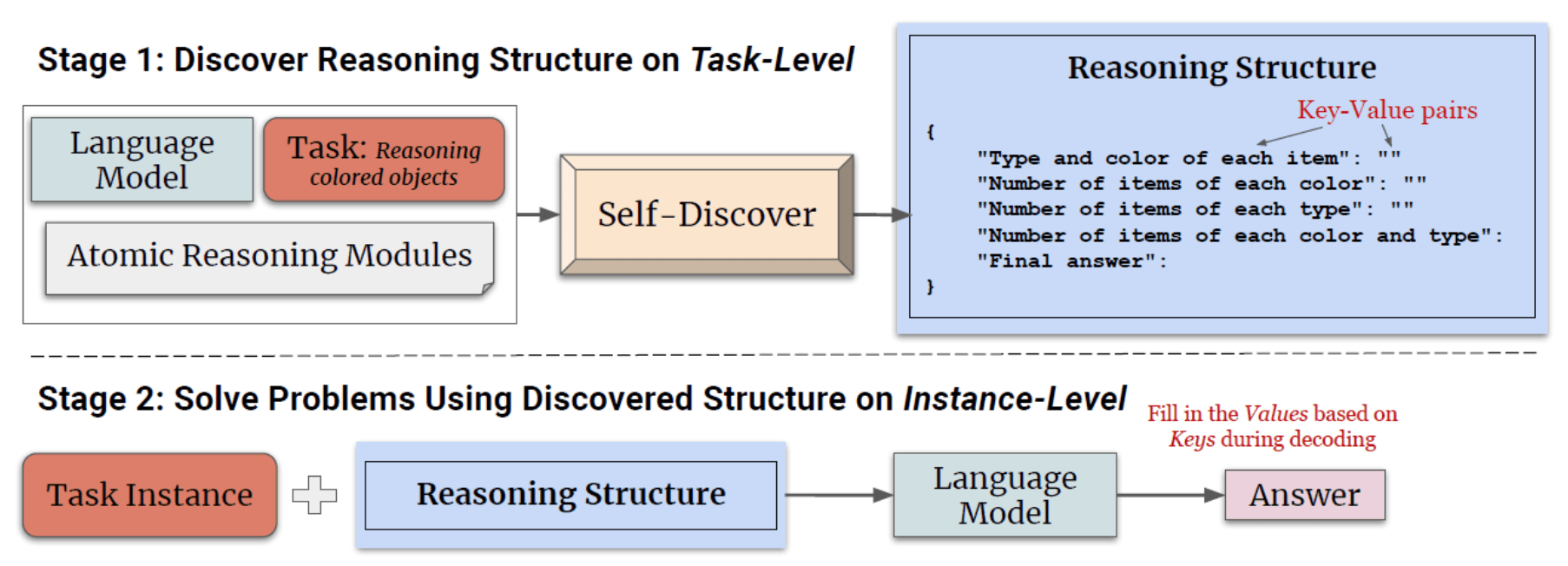
3)Self Discover
这种方法的核心是一个自发现过程,它允许大型语言模型在没有明确标签的情况下,自主地从多个原子推理模块(如批判性思维和逐步思考)中选择,并将其组合成一个推理结构。Self-Discover框架包含两个主要阶段,如下图所示:
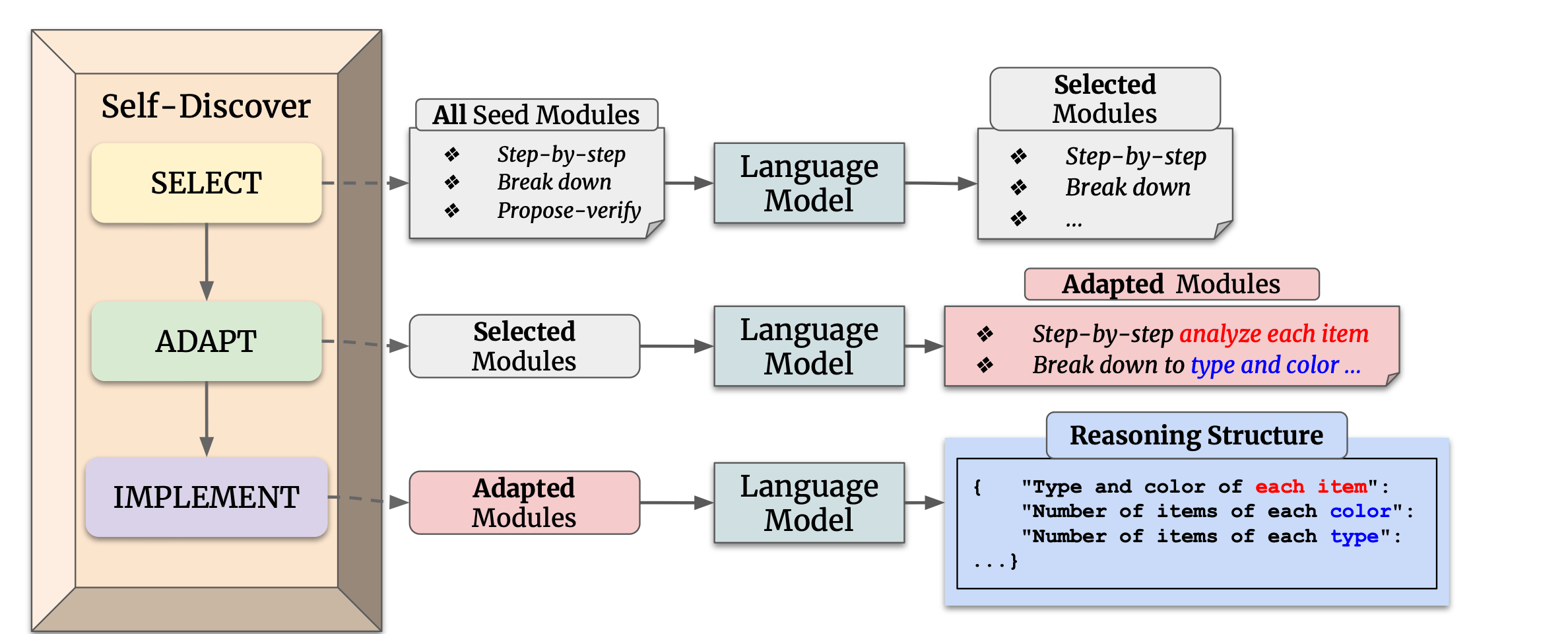
阶段一:自发现特定任务的推理结构
包含三个主要动作:选择(SELECT)、适应(ADAPT)和实施(IMPLEMENT)。
- 选择:在这个阶段,模型从一组原子推理模块中选择对于解决特定任务有用的模块。模型通过一个元提示来引导选择过程,这个元提示结合了任务示例和原子模块描述。选择过程的目标是确定哪些推理模块对于解决任务是有助的。
- 适应:一旦选定了相关的推理模块,下一步是调整这些模块的描述使其更适合当前任务。这个过程将一般性的推理模块描述,转化为更具体的任务相关描述。例如对于算术问题,“分解问题”的模块可能被调整为“按顺序计算每个算术操作”。同样,这个过程使用元提示和模型来生成适应任务的推理模块描述。
- 实施:在适应了推理模块之后,Self-Discover框架将这些适应后的推理模块描述转化为一个结构化的可执行计划。这个计划以键值对的形式呈现,类似于JSON,以便于模型理解和执行。这个过程不仅包括元提示,还包括一个人类编写的推理结构示例,帮助模型更好地将自然语言转化为结构化的推理计划。
阶段二:应用推理结构
完成阶段一之后,模型将拥有一个专门为当前任务定制的推理结构。在解决问题的实例时,模型只需遵循这个结构,逐步填充JSON中的值,直到得出最终答案。
[3] 高级推理框架,Reflexion和LATS
大模型经过初级和中级推理框架的优化后,能准确地处理一些相对简单的问题,但是在处理复杂的推理任务时,仍然会显得力不从心。因此,高级推理框架的核心主张就是,通过强化学习技术进行训练,专门用于思考链条更长、反思环节更多的复杂推理任务。
1)Reflexion
Reflexion的本质是强化学习,完整的Reflexion框架由三个部分组成:
- 参与者(Actor):根据状态观测量生成文本和动作。参与者在环境中采取行动并接受观察结果,从而形成轨迹。
- 评估者(Evaluator):对参与者的输出进行评价。具体来说,它将生成的轨迹(也被称作短期记忆)作为输入并输出奖励分数。根据人物的不同,使用不同的奖励函数(决策任务使用LLM和基于规则的启发式奖励)。
- 自我反思(Self-Reflection):这个角色由大语言模型承担,能够为未来的试验提供宝贵的反馈。自我反思模型利用奖励信号、当前轨迹和其持久记忆生成具体且相关的反馈,并存储在记忆组件中。Agent会利用这些经验(存储在长期记忆中)来快速改进决策。
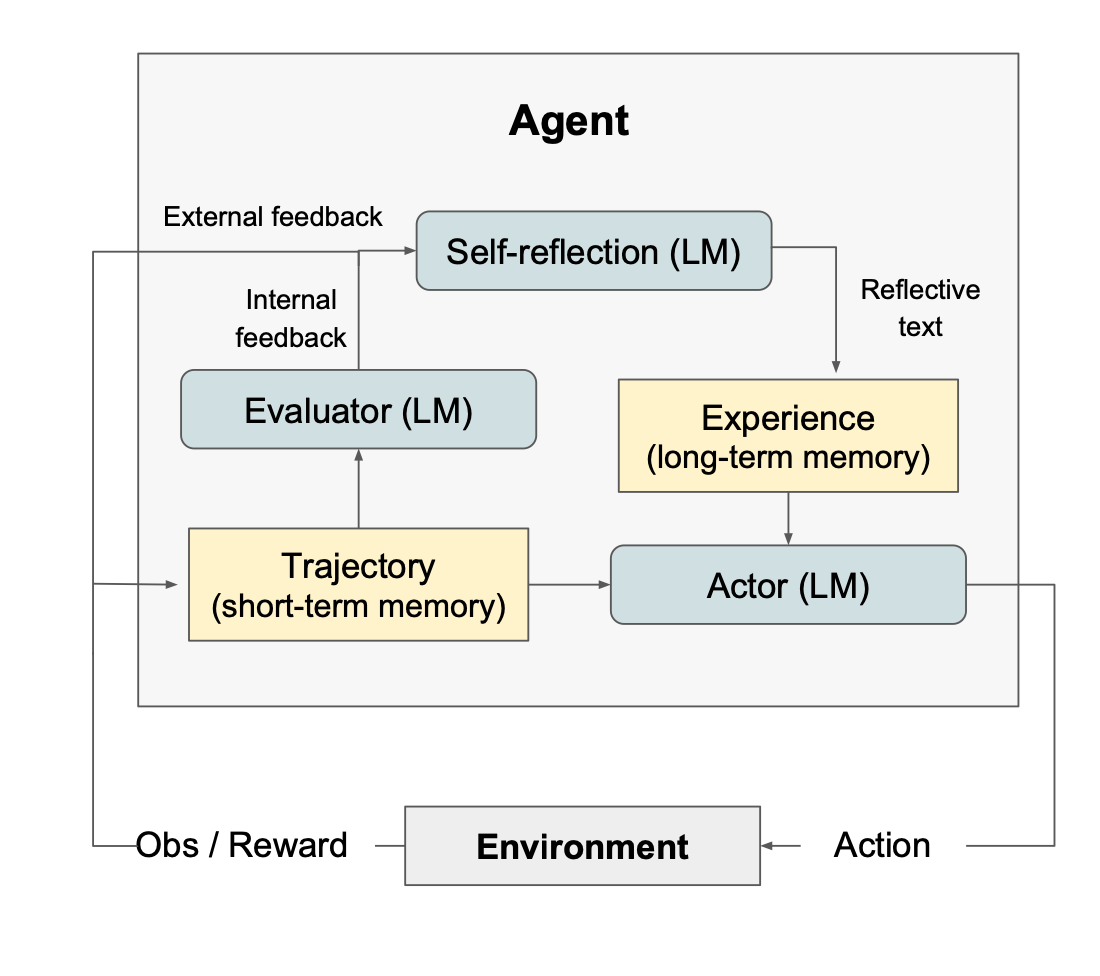
因此,Reflexion模式非常适合以下情况:
- 大模型需要从尝试和错误中学习:自我反思旨在通过反思过去的错误并将这些知识纳入未来的决策来帮助智能体提高表现。这非常适合大模型需要通过反复试验来学习的任务,例如决策、推理和编程。
- 传统的强化学习方法失效:传统的强化学习(RL)方法通常需要大量的训练数据和昂贵的模型微调。自我反思提供了一种轻量级替代方案,不需要微调底层语言模型,从而使其在数据和计算资源方面更加高效。
- 需要细致入微的反馈:自我反思利用语言反馈,这比传统强化学习中使用的标量奖励更加细致和具体。这让大模型能够更好地了解自己的错误,并在后续的试验中做出更有针对性的改进。
2)LATS
LATS,全称是Language Agent Tree Search,说的更直白一些,LATS = Tree search + ReAct + Plan and Execute+ Reflexion。LATS的工作流程如下图所示,包括以下步骤:
- 选择 (Selection):即从根节点开始,使用上置信区树 (UCT) 算法选择具有最高 UCT 值的子节点进行扩展。
- 扩展 (Expansion):通过从预训练语言模型 (LM) 中采样 n 个动作扩展树,接收每个动作并返回反馈,然后增加 n 个新的子节点。
- 评估 (Evaluation):为每个新子节点分配一个标量值,以指导搜索算法前进,LATS 通过 LM 生成的评分和自一致性得分设计新的价值函数。
- 模拟 (Simulation):扩展当前选择的节点直到达到终端状态,优先选择最高价值的节点。
- 回溯 (Backpropagation):根据轨迹结果更新树的值,路径中的每个节点的值被更新以反映模拟结果。
- 反思 (Reflection):在遇到不成功的终端节点时,LM 生成自我反思,总结过程中的错误并提出改进方案。这些反思和失败轨迹在后续迭代中作为额外上下文整合,帮助提高模型的表现。
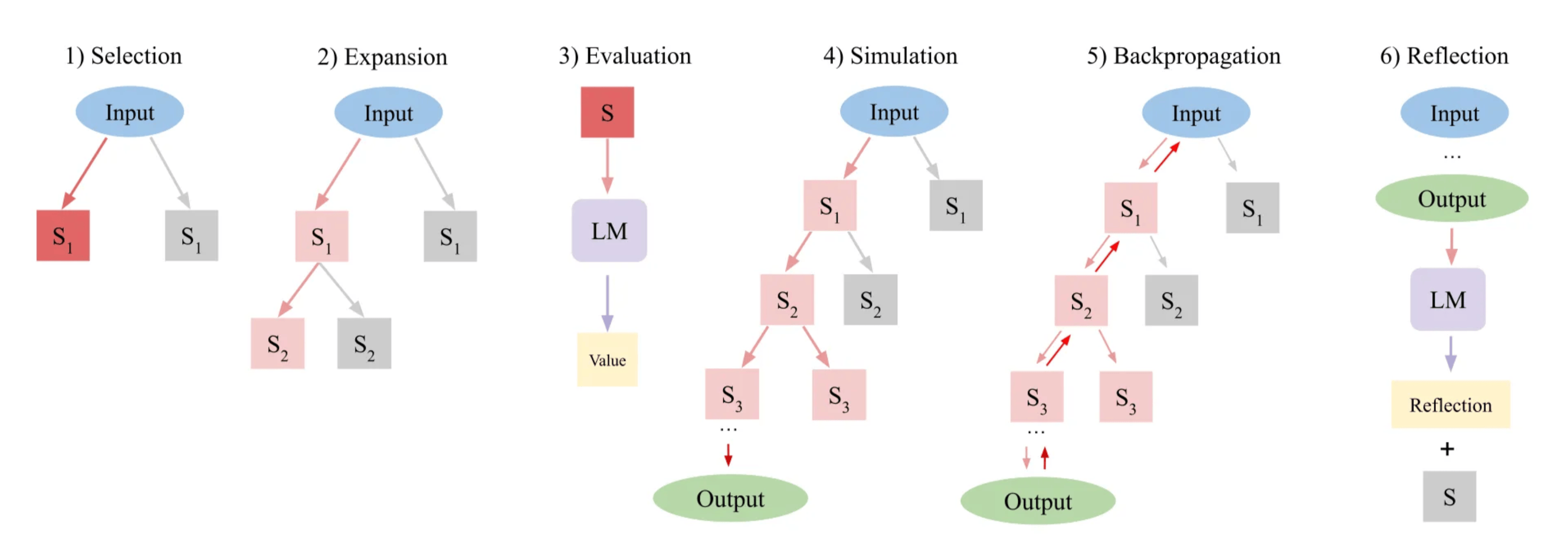
当采取行动后,LATS不仅利用环境反馈,还结合来自语言模型的反馈,以判断推理中是否存在错误并提出替代方案。这种自我反思的能力与其强大的搜索算法相结合,使得LATS更适合处理一些相对复杂的任务。
九、数字与言论
1、我们花费了地球上一半的工程努力,来为每个应用程序添加 AI 聊天机器人,而世界上一半的行业还没有弄清楚如何经常备份数据库。推出 AI 产品的公司数量,远远超过了实际用例的数量。——《如果你再提 AI,我就要发作了》
2、许多开发者不喜欢前端,主要有两个原因。一是前端太受流行风潮的影响,二是前端开发者主要由年轻的/新入行的/自学的人员组成,他们“不断发现”新范式。这使得前端技术极不稳定,你学不到真正长久的东西。——Hacker News
3、大学课程《计算机体系结构》,选择的 CPU 往往不是流行的架构,比如 x86 和 ARM,而是一些很原始、早被淘汰的 CPU。原因是这门课的目的是架构的思想,而不是细节,因此选择一个“原始” CPU 更有帮助。——StackExchange
4、AI 的危险在于,它让你跳过思考,让机器填补思想的空白。我们需要 AI 使我们增加思考,而不是减少思考。我们每外包一个想法,就会错失一次成长的机会。——《扭转人工智能局面》
5、费马大定理是一个极困难的数学猜想,自从1637年提出后,直到1993年才解决。这个定理没有任何实际应用,只是用来提醒人们数学是多么深奥。——《费马大定理》
6、简单性是一种优点,但糟糕的是,复杂的东西卖得更好。——Edsger Dijkstra,著名计算机科学家
7、一家名为 Suno 的公司发布了一个 AI 音乐模型,只要你描述想听什么,它就会生成那样的音乐。这件事标志着一个音乐时代的结束,以及下一个音乐时代的开始,AI 已经到了改变所有音乐的时刻,但是音乐家们似乎还浑然不觉。——《音乐永远变了》
8、大家都认为NVIDIA是销售GPU,但是实际上他们是在销售CUDA加速运算库,GPU只是非常昂贵又必不可少的独家配件。——Hacker News
9、我的职业建议是,任何工作要么让你学习,要么让你赚钱。如果既学不到新东西,又赚不到钱,你就应该走了。——Garry Tan,硅谷风险投资家
10、一家媒体公司发现,上个世纪90年代它用来存档的上万个硬盘驱动器,已经有五分之一无法读取,上面的资料可能全部遗失。人类生活已经“数字化”了,除非定期维护和备份数字介质,否则几十年后,上面的资料就可能不存在,根本无法像纸张那样,无人维护也能流传几百上千年。——《是时候讨论硬盘了》
11、如果你一生只看过两部电影,那么你很可能会认为这两部电影都相当不错。但如果你看过一千部电影,你就会真正知道如何分辨优秀电影。这就是为什么多看可以提高辨别力。——《提升品味以打造更好的产品》
12、OpenAI 的估值高达1500亿美元,很多人认为它不值这么多。(1)市场上有很多规模更小、价格更便宜的模型可供选择,部分是开源的。(2)随时可能有更突破的模型出现,取代它的位置。(3)OpenAI 很多员工离职,流动到其他公司。——《经济学家》
13、Uber 打车的算法是,如果你的手机快没电了,它就会显示更高的价格。——《Uber 发现手机快没电时乘客愿付高价》
14、债务定义了你的未来,当你的未来被债务定义时,希望就开始破灭。这就是债务的最大问题,它限制了你的人生选择和灵活性。——肯特·纳伯恩(Kent Nerburn),美国作家